SQLite: как организовывать таблицы.
Организация данных — все равно, что поддержание порядка на рабочем месте. Хорошо всегда знать, где что находится, и в случае необходимости освобождать больше места для хранения или работы.
В настоящее время мир состоит из библиотек реляционных и нереляционных баз данных, причем и у тех, и у других свои преимущества и недостатки. В этой статье сфокусируемся на рассмотрении реляционных баз данных.
Увидим, как с помощью библиотеки SQ
SQLite: как организовывать таблицы...
Организация данных — все равно, что поддержание порядка на рабочем месте. Хорошо всегда знать, где что находится, и в случае необходимости освобождать больше места для хранения или работы.
В настоящее время мир состоит из библиотек реляционных и нереляционных баз данных, причем и у тех, и у других свои преимущества и недостатки. В этой статье сфокусируемся на рассмотрении реляционных баз данных.
Увидим, как с помощью библиотеки SQLite создаются таблицы и как минимизируется добавление неправильных данных через предоставление дополнительной информации в момент построения таблицы и после ее создания. Но прежде попытаемся дать общее понятие о том, что представляет собой эта библиотека SQLite.
SQLite
SQLite — это реляционная база данных, основанная на языке SQL. «Реляционная» означает, что в базе данных есть таблицы, которые связаны друг с другом через общие атрибуты. Эти таблицы представляют собой двумерные массивы информации, состоящие из строк (или записей) и столбцов (или атрибутов).
Ниже показан пример таблицы с тремя записями и тремя атрибутами, содержащими различные типы данных. Построение примера осуществлено с использованием приложения DB Browser для SQLite.
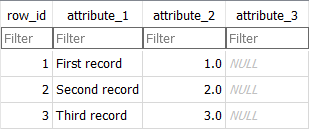
SQL — это стандартизированный язык. Тем не менее разработчики вольны соблюдать или не соблюдать стандарты до определенной степени. Это зависит от конкретной реализации. Одной из таких реализаций и является SQLite. В отличие от MySQL или PostgreSQL, это более простая библиотека, созданная для использования локально и без необходимости внешних серверов.
Бессерверность SQLite обусловливает наличие других функциональных особенностей. Во-первых, это независимость, подразумевающая то, что SQLite не нуждается во внешних ресурсах и поэтому пригодна для использования в любой среде. Во-вторых, это нулевая конфигурация, ведь сервера нет и настраивать нечего.
А кроме того, SQLite транзакционная: все изменения либо происходят полностью, либо не происходят вообще. Транзакции должны соответствовать набору правил под названием ACID. Каждая буква этого акронима обозначает определенные требования.
A расшифровывается как Atomicity («Атомарность») и означает, что изменения происходят в целом и их нельзя разделить. C значит Consistency («Согласованность») и предполагает, что состояние базы данных должно оставаться согласованным после того, как результаты транзакции зафиксированы или произошел откат к предыдущему состоянию. I означает Isolation («Изолированность») и указывает на то, что транзакции видны только в текущем сеансе. Наконец, D расшифровывается как Durability («Долговечность») и означает, что изменения должны быть сохранены.
А теперь создадим базу данных с информацией о расах и подрасах из игры Dungeons and Dragons («Подземелья и драконы»). Почему я выбрал ее? Уж очень она отличается от традиционных примеров и в игру эту мы с удовольствием играем с друзьями.
Начнем создание базы данных с использования следующих команд SQLite в командной строке:
cd C:\Projects\SQLite C:\Projects\SQLite>sqlite3 DnD.dbПервой командой меняем каталог в файл, в котором будет база данных, а второй создаем базу данных, активировав библиотеку sqlite3 и выбрав для нее название.
SQLite — гибкая библиотека с расширениями, которые задействуются для файла базы данных. Такие расширения, как .db, .sqlite или .sqlite3, используются без проблем. Теперь создадим первую таблицу.
Создание таблицы
Таблицы — это структуры, которые удерживают данные, вставленные в реляционные и подобные им базы данных. Вот обобщенное представление кода для создания таблицы:

Начинаем с ввода команды CREATE TABLE, за которой следует название таблицы в table_name. В квадратные скобки заключен необязательный код. Команда IF NOT EXISTS используется для того, чтобы SQLite проверила отсутствие этого названия среди уже имеющихся таблиц, прежде чем создавать новую.
В круглых скобках указываем имена атрибутов или столбцов, их типы данных и ограничения на уровне атрибутов или таблицы. Типы данных и ограничения приводить необязательно, но лучше их указать. Так пользователь будет понимать, какая информация хранится в каждом атрибуте.
О том, что такое типы данных и ограничения, расскажем позже. А пока достаточно знать, что они существуют и определяются в момент создания таблицы.
Точка с запятой указывает SQLite, что фрагмент кода завершен и готов к обработке. Создадим новую таблицу races, которая будет содержать информацию для различных рас:

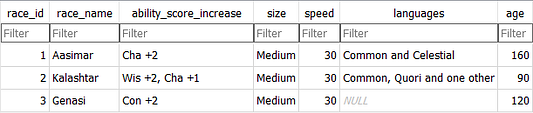
Чтобы вы понимали, race_name — это название той или иной расы в игре «Подземелья и драконы», например Эльфы, Гномы или Дворфы (будем использовать здесь чуть более экзотические примеры). А в ability_score_increase содержатся оценки способностей, по которым раса по своей природе превосходит другие, например Aasimar более харизматичны, поэтому их харизма выше на два пункта.
Атрибут size — это то, насколько велики в среднем по размеру представители той или иной расы, как правило они либо маленькие, либо средние. Speed — это максимальное расстояние, которое представители расы способны пробежать за один раунд сражения. Languages — это языки, на которых говорит раса, а age — это средняя продолжительность жизни представителей расы.
race_id — это число, присваиваемое расе как целочисленное свойство. К этому важному свойству мы вернемся позже, когда будем говорить об ограничениях.
Многие скажут, что многовато новой информации для того, кто никогда не играл в эту настольную игру или даже не слышал о ней. На самом деле вовсе и не нужно понимать, что означают атрибуты. Что действительно важно — это их типы данных и ограничения.
А теперь заполним таблицу. Для этого напишем оператор INSERT с тремя записями:

Посмотрите: мы передаем название таблицы, а также ее атрибуты, куда вставляем значения, за которыми идут фактические, желаемые нами значения. Вот данные, сохраняющиеся в races:
Бывает обидно написать так много текста в командной строке, а потом обнаружить опечатку. Ведь в этом случае командная строка не позволит вернуться и исправить ее. SQLite предлагает возможность использования текстового файла с помощью команды .read.
Тут все просто: пишем код для создания таблицы, вставляем значения в текстовый файл и проверяем, нет ли опечаток. Если все правильно, сохраняем файл под любым именем и вводим его в командной строке вот так: .read имя файла. Представьте, что операторы CREATE TABLE и INSERT у нас выше разделены пустой строкой в текстовом файле races.txt:
sqlite>.read races.txt автоматически создаст таблицу и заполнит ее.
Теперь мы умеем создавать таблицы и вставлять в них значения. Дальше узнаем, что такое типы данных и ограничения и как они помогают идентифицировать и поддерживать информацию в таблице. Сначала рассмотрим типы данных.
Типы данных
SQLite поддерживает пять основных типов данных, которые определяются в момент создания новой таблицы: TEXT, INTEGER, REAL, GLOB и NULL. Мы видели выше, что в созданной таблице races содержатся TEXT (текстовые) и INTEGER (целочисленные) типы данных.
Вообще говоря, тип данных TEXT представляет собой текстовую информацию, заключенную в кавычки или отделенную строками. В таблице races атрибут race_name установлен для хранения данных TEXT текстового типа, а строки Aasimar, Kalashtar и Genasi заполняют этот атрибут.
Тип данных INTEGER представляет собой целые числа (положительные или отрицательные) размером от 1 до 8 байтов. Speed — хороший пример того, где использовать целые числа, потому что этот атрибут обозначает количество футов, которые персонаж способен пробежать в раунде сражения.
REAL — это тип данных, содержащий числа длиной более 8 байтов или десятичные и экспоненциальные числа, например 1,5 или 2⁴.
NULL используется для отсутствующей или неизвестной информации. Допустим, нам не удалось найти, на каких языках говорят представители расы Genasi. В этом случае на какое-то время будем сохранять это значение как NULL.
Наконец, есть еще тип данных BLOB. Он расшифровывается как «большой двоичный объект» и хранит любые данные. В нашем наборе данных типы данных REAL и BLOB не используются.
Тип данных Datetime не поддерживается SQLite, но такая информация все равно сохраняется как тип данных TEXT, REAL или INTEGER при условии корректных преобразований. Например, данные timestamp сохраняются как INTEGER.
Имейте в виду, что SQLite, в отличие от других библиотек SQL, принимает различные данные для хранения в атрибутах, тип данных которых предопределен. Например, определение атрибута как содержащего данные TEXT не помешает SQLite принимать целые числа или любые другие типы данных.
И тем не менее определение типа данных дает пользователю прозрачный намек на то, какие данные должны храниться в каждом атрибуте, позволяя лучше организовывать таблицы.
Ограничения
Ограничения помогают устанавливать границы в атрибутах, значениях по умолчанию или связях между таблицами. Начнем с последнего. Есть два ограничения, которые играют важную роль в том, что называется нормализацией. Это PRIMARY KEY (первичный ключ) и FOREIGN KEY (внешний ключ).
Прежде чем переходить к более подробному рассмотрению этих двух ограничений, создадим новую таблицу subraces, содержащую связь с races, и попробуем понять, что такое нормализация.

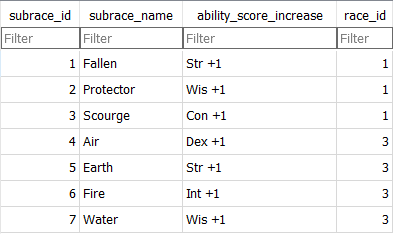
В таблице subraces содержится атрибут race_id, который принимает значения INTEGER (целочисленного типа данных) и ссылается на столбец race_id в таблице races с помощью строки FOREIGN KEY (race_id) REFERENCES races (race_id).
Благодаря такой ссылке мы сохраняем информацию о подгруппах, сводя к минимуму повторы этой информации в базе данных. Посмотрите на значения в таблице subraces:
Без нормализации нам пришлось бы создавать таблицу типа races_subraces со следующим кодом:

И следующими значениями:
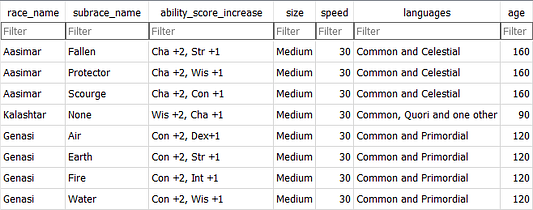
Особой разницы, возможно, и не заметно из-за не слишком большого количества атрибутов и записей. Присмотритесь, и вы увидите довольно много повторяющихся значений, а именно в атрибутах age, languages, speed, size и race_name. А представьте, сколько места экономится в больших базах данных с тысячами взаимосвязанных записей и атрибутов!
Вот как выглядят связи между расами и подрасами на схеме:
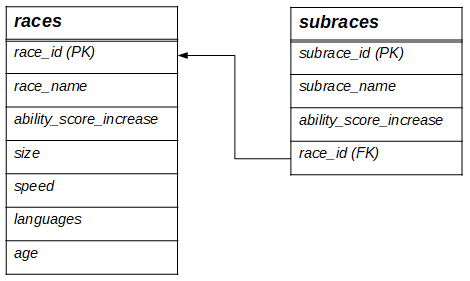
Но мы до сих пор не рассказали, что означают ON DELETE CASCADE и ON UPDATE NO ACTION.
Первое фактически означает, что если удалить, например, расу Genasi (race_id = 3) из таблицы races, то SQLite автоматически удалит и подрасы с race_id = 3 из таблицы subraces.
ON UPDATE NO ACTION необходимо потому, что если изменить любую запись в таблице races, которая связана со внешним ключом в таблице subraces, например обновив атрибут languages для Genasi, то таблицаsubraces станет совершенно пустой.
Кроме того, различные атрибуты определяют как PRIMARY KEY (первичный ключ). Это делается для создания более сложных связей между большим количеством таблиц (больше чем двух таблиц):
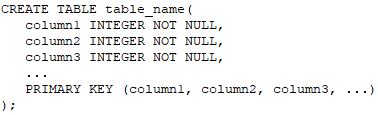
Заметили здесь еще одно ограничение? Да, это NOT NULL. Оно вынуждает атрибуты не принимать значения NULL, т. е. пустые значения. NOT NULL обычно используется в столбцах идентификаторов. Хотя не только в них, но в любом атрибуте, если пользователь сочтет, что значения этого атрибута не должны быть неизвестными или отсутствующими.
То, что у атрибута записи не имеется значения, не предполагает, что вместо него обязательно должен быть NULL.
Обратите внимание на строку None в столбце subrace_name таблицы races_subraces с названием расы (race_name) Калаштары. NULL здесь не имел бы смысла, потому что у Калаштаров просто нет подрас. То есть нельзя сказать, что эта информация недостающая или неизвестная.
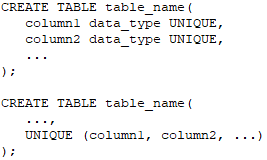
Если пользователь решит, что у атрибута для всех записей должны быть разные значения, он должен будет использовать ограничение UNIQUE. В этом случае, если в столбец с ограничением UNIQUE попытаться вставить новую строку с повторяющимся значением, SQLite выдаст ошибку.
Посмотрите на столбец races_name в таблице races: в нем есть это ограничение и оно здесь кстати. Ведь у разных рас должны быть уникальные названия, чтобы отличать одну от другой.
UNIQUE определяется на уровне столбца (вверху) или на уровне таблицы (внизу):
Переходим к следующему ограничению CHECK. Оно позволяет пользователю определить выражение, которое не должно быть нарушено вставляемым значением.
Выберем таблицу races и убедимся, что значения, вставленные в атрибут speed, всегда состоят из двух цифр (так как у нас нет рас с большей или меньшей скоростью, чем эта). Оставим пока в покое таблицу races и создадим новую с ограничением CHECK:

Теперь попробуем вставить строку с атрибутом speed 300:

Возникнет ошибка. Почему? Потому что нарушено ограничение CHECK и эта новая строка значений не будет вставлена в таблицу.
Так же, как и UNIQUE, CHECK определяется на уровне столбца (вверху) или таблицы (внизу):

Осталось последнее ограничение: DEFAULT. Есть один язык, который понимают все расы, он называется Common («общий» язык). Добавим ограничение DEFAULT, установим ему значение Common («общий») и вставим строку без указания атрибута languages:

Как видите, атрибуту language не передано никакого значения. Однако, определив Common в качестве языка по умолчанию, мы получим следующий результат:

Это ограничения, принятые в SQLite. Они помогают пользователю создавать взаимосвязи между более простыми, удобными для восприятия таблицами, а также в определенной степени управлять данными перед их вставкой в таблицы.
Выберемся теперь из таблиц и посмотрим, как используется команда CREATE TRIGGER для создания границ.
Триггеры
Триггеры автоматически выполняют заданные пользователем действия всякий раз, когда строка вставляется, удаляется или обновляется в связанной с ней таблице. Они позволяют пользователю осуществлять более сложное управление значениями, поступающими в таблицы и покидающими их. Общий синтаксис создания триггера выглядит следующим образом:
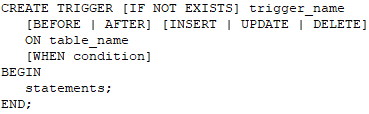
Сначала создаем триггер и даем ему название. Затем решаем, когда TRIGGER сработает. Это может быть до или после любого из следующих трех событий: INSERT, UPDATE или DELETE.
Нужно указать таблицу, в которой будет действовать этот триггер, а затем условие триггера (необязательное) после оператора WHEN. Наконец, указываем логику триггера между BEGIN и END.
В зависимости от события доступ к атрибуту осуществляется с помощью ссылок OLD и NEW в виде OLD.column_name и NEW.column_name.
Для события INSERT используется NEW, потому что вставляется новая строка. Для UPDATE используется и NEW, и OLD, потому что старая строка или значение обновляется новым. Для действия DELETE используется OLD, потому что удаляется старая строка или значение.
Вернемся к таблице subraces. Значения и строки в атрибуте ability_score_increase можно эмулировать, применяя ___ +1, с помощью трех подстановочных знаков подчеркивания.
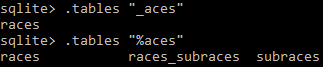
Подстановочные знаки заменяют символы. Есть два подстановочных знака: подчеркивание _ (которое заменяет только один символ) и процент % (заменяет любое количество символов). Например, если искать таблицы с помощью команды .table, то при вводе .tables “_aces” SQLite найдет таблицу races, а при вводе .table “%aces” найдет таблицы races, subraces и races_subraces.
В игре «Подземелья и драконы» шесть параметров, по которым оцениваются способности. Три физических параметра: сила, ловкость, телосложение. И три психологических: интеллект, мудрость, харизма. По этим характеристикам персонажи распределяются по расам и подрасам. Сокращенно эти параметры обозначаются так: Str, Dex, Con, Int, Wis и Cha.
В создаваемом нами триггере будет использоваться строка с тремя подстановочными знаками подчеркивания специально для сокращенных названий. Так что, если вместо сокращенного Cha +1 передать Charisma +1, триггер не выполнится и выдаст ошибку: Ability score is not shortened («Параметр для оценки способностей не сокращен»).

Если триггер больше не нужен, избавляемся от него, либо удаляя все таблицы, с которыми он связан, либо удаляя его самого:
С триггерами легче минимизировать ошибки. Стоит только проявить творческий подход, как тут же находятся и другие способы использования триггеров для контроля за потоком данных. Тем не менее ничто не гарантирует отсутствия ошибок, и дальше мы расскажем о том, как справляться с еще большими ошибками на уровне базы данных.
Резервное копирование баз данных
Всякий раз, выполняя какие-то действия с базой данных, следует создавать резервную копию. Ведь неправильные инструкции легко приводят к тому, что целиком удаляются строки или заменяются атрибуты, и на исправление всего этого требуется много времени.
Чтобы защититься от любых нежелательных изменений в базе данных, есть возможность сделать резервную копию и восстановить базу данных с помощью .backup backupfilename и .restore backupfilename. Название backupfilename не должно совпадать с названием базы данных.
Подведем итоги
Мы обсудили, что такое SQLite, как создавать таблицы и как правильно хранить данные. А начали все со стандартизированного языка SQL.
Кроме того, мы рассказали о преимуществах SQLite: отсутствии необходимости настраивать сервер для ее использования и правилах, которые соблюдаются здесь при совершении транзакции.
Затем перешли к созданию таблиц, определению атрибутов и установке для них типов данных и ограничений.
Мы также обсудили общие типы данных, которые используются в SQLite для хранения информации. Убедились, что SQLite не сохраняет тип данных datetime, но здесь такие данные легко сохраняются с помощью основных используемых типов данных.
Затем мы перешли к ограничениям. Они добавляют функциональность таблицам либо через нормализацию с помощью ключей, которые связывают таблицы, устанавливая значения по умолчанию или сверяя вставляемые значения с выражением, либо не допуская значения NULL.
Мы также обсудили то, как с помощью триггеров поддерживается информация в таблице благодаря более глубокому контролю того, что в ней подлежит изменению. Триггеры используются до или после момента добавления, обновления и удаления любых необходимых нам строк или значений.
Наконец, мы кратко рассказали о том, как создавать резервные копии и восстанавливать базу данных.