Слияние больших языковых моделей с помощью mergekit.
Под слиянием моделей подразумевают технику, которая объединяет две или более LLM в одну модель. Это относительно новый и экспериментальный метод, позволяющий экономно создавать новые модели (GPU не требуется). Слияние работает на удивление хорошо — техника привела к появлению множества самых передовых моделей, представленных на Open LLM Leaderboard.
В этом руководстве мы реализуем слияние с помощью библиотеки mergekit. Мы рассмотрим четыре ме?
Слияние больших языковых моделей с помощью mergekit...
Под слиянием моделей подразумевают технику, которая объединяет две или более LLM в одну модель. Это относительно новый и экспериментальный метод, позволяющий экономно создавать новые модели (GPU не требуется). Слияние работает на удивление хорошо — техника привела к появлению множества самых передовых моделей, представленных на Open LLM Leaderboard.
В этом руководстве мы реализуем слияние с помощью библиотеки mergekit. Мы рассмотрим четыре метода слияния и приведем примеры конфигураций. Затем используем mergekit для создания собственной модели, Marcoro14–7B-slerp, которая была признана лучшей на Open LLM Leaderboard (02/01/24).
Код доступен на GitHub и Google Colab. Рекомендую использовать мой автоматизированный ноутбук LazyMergekit для легкого запуска mergekit.
Алгоритмы слияния
В этом разделе мы сосредоточимся на четырех механизмах, которые в настоящее время реализованы в mergekit. Обратите внимание: существуют и другие методы, такие как линейный и Task Arithmetic.
1. SLERP
Сферическая линейная интерполяция (SLERP) — это метод, используемый для плавной интерполяции между двумя векторами. Он поддерживает постоянную скорость изменения и сохраняет геометрические свойства сферического пространства, в котором находятся векторы.
Есть несколько причин, по которым SLERP отдают предпочтение перед традиционной линейной интерполяцией. Например, в высокоразмерных пространствах линейная интерполяция может привести к уменьшению величины интерполированного вектора (т. е. она уменьшает масштаб весов). Более того, изменение направления весов часто представляет собой более значимую информацию (например, для изучения и презентации признаков), чем величина изменения.
SLERP реализуется с помощью следующих шагов.
- Приведение входящих векторов к единичной длине, чтобы они представляли направления, а не величины.
- Вычисление угла между этими векторами с помощью их скалярного произведения.
- Если векторы почти коллинеарны, то по умолчанию используется линейная интерполяция для повышения эффективности. В противном случае SLERP вычисляет коэффициенты масштабирования на основе коэффициента интерполяции
t(t=0= 100% первого вектора,t=1= 100% модели 2) и угла между векторами. - Эти коэффициенты используются для взвешивания исходных векторов, которые затем суммируются для получения интерполированного вектора.
В настоящее время SLERP является наиболее популярным методом слияния, но с его помощью можно объединить только две модели за раз. При этом существует возможность иерархического объединения нескольких моделей, как показано в Mistral-7B-Merge-14-v0.1.
Пример конфигурации:
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-1218
layer_range: [0, 32]
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: OpenPipe/mistral-ft-optimized-1218
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
Это классическая конфигурация SLERP, применяемая к каждому слою обеих моделей. Обратите внимание: мы вводим градиент значений для коэффициента интерполяции t. Параметры для слоев самовнимания и MLP будут использовать различные комбинации OpenPipe/mistral-ft-optimized-1218 и mlabonne/NeuralHermes-2.5-Mistral-7B. Остальные слои представляют собой смесь двух моделей в пропорции 50/50.
Итоговую модель можно найти на хабе ресурса Hugging Face по ссылке.
2. TIES
Система TIES-Merging, представленная в этой статье Ядавом и другими, предназначена для эффективного объединения нескольких моделей, специфичных для конкретной задачи, в одну многозадачную модель. Она решает две основные проблемы, связанные с объединением моделей.
- Избыточность параметров. TIES выявляет и устраняет избыточные параметры в моделях для конкретных задач. Это достигается путем фокусировки на изменениях, сделанных во время тонкой настройки, выявления топ-k % наиболее значимых изменений и отбрасывания всего остального.
- Разногласия между знаками параметров. Когда разные модели предлагают противоположные корректировки одного и того же параметра, возникают противоречия. TIES-Merging разрешает подобные конфликты, создавая вектор с единым знаком, который представляет наиболее доминирующее направление изменений во всех моделях.
Реализация TIES-Merging состоит из трех этапов.
- Обрезка. Уменьшение избыточности в моделях, специфичных для конкретной задачи, с сохранением только части наиболее значимых параметров (параметр плотности) и сбрасыванием остальных в ноль.
- Выбор знака. Устранение конфликтов знаков в разных моделях путем создания вектора с единым знаком на основе наиболее доминирующего направления (положительного или отрицательного) с точки зрения суммарной величины.
- Раздельное слияние. Усреднение значений параметров, которые согласуются с вектором с единым знаком (за исключением нулевых значений).
В отличие от SLERP, TIES может объединять несколько моделей одновременно.
Пример конфигурации:
models:
- model: mistralai/Mistral-7B-v0.1
# параметры для базовой модели не нужны
- model: OpenPipe/mistral-ft-optimized-1218
parameters:
density: 0.5
weight: 0.5
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
parameters:
density: 0.5
weight: 0.3
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
normalize: true
dtype: float16
Эта конфигурация применяется при использовании Mistral-7B в качестве базовой модели для расчета дельта-весов. Мы объединяем те же две модели: mistral-ft-optimized-1218 (50%) и NeuralHermes-2.5-Mistral-7B (30%) с нормализацией. В этом случае показатель плотности означает, что мы сохраняем только 50% параметров каждой модели (другая половина берется из базовой модели).
Обратите внимание: в конфигурации сумма весов не равна 1, но параметр normalize: true автоматически нормализует их внутренне. Указанная конфигурация вдохновлена параметрами, предоставленными автором OpenHermes-2.5-neural-chat-7b-v3–1–7B.
Итоговую модель можно найти на хабе Hugging Face по ссылке.
3. DARE
В системе DARE, представленной Ю и другими (2023), используется подход, аналогичный TIES, с двумя основными отличиями.
- Отсечение. DARE случайным образом возвращает тонко настроенные веса к их исходным значениям (значениям базовой модели).
- Перемасштабирование. DARE перемасштабирует веса, чтобы ожидания результатов модели оставались примерно теми же. Происходит добавление перемасштабированных весов двух (или более) моделей к весам базовой модели с коэффициентом масштабирования.
Есть два варианта реализации этого метода в mergekit: с шагом выбора знака TIES (dare_ties) и без него (dare_linear).
Пример конфигурации:
models:
- model: mistralai/Mistral-7B-v0.1
# Параметры для базовой модели не нужны
- model: samir-fama/SamirGPT-v1
parameters:
density: 0.53
weight: 0.4
- model: abacusai/Slerp-CM-mist-dpo
parameters:
density: 0.53
weight: 0.3
- model: EmbeddedLLM/Mistral-7B-Merge-14-v0.2
parameters:
density: 0.53
weight: 0.3
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
int8_mask: true
dtype: bfloat16
В этой конфигурации мы объединяем три различные модели на основе Mistral-7B с помощью dare_ties. На этот раз я выбрал веса, которые в сумме равны 1 (сумма должна быть между 0,9 и 1,1). Параметр плотности немного выше, чем рекомендуется в работе (<0,5), но, похоже, он дает стабильно лучшие результаты (см. обсуждение).
Вы можете найти модель на хабе Hugging Face по ссылке. Это также лучшая модель слияния, представленная в данной статье — она превосходит даже Marcoro14–7B-slerp.
4. Passthrough
Метод passthrough значительно отличается от предыдущих. Объединяя слои из разных LLM, он может создавать модели с экзотическим числом параметров (например, до 9 миллиардов с двумя моделями по 7 миллиардов параметров). В сообществе такие модели часто называют “франкенмерджами” или “моделями Франкенштейна”.
Эта техника пока еще переживает экспериментальный период, но с ее помощью удалось создать впечатляющие модели, такие как goliath-120b с использованием двух моделей Llama 2 70B. Недавно выпущенная SOLAR-10.7B-v1.0 также основана на той же идее, названной в этой работе “масштабированием по глубине”.
Пример конфигурации:
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-1218
layer_range: [0, 32]
- sources:
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
layer_range: [24, 32]
merge_method: passthrough
dtype: bfloat16
Итоговая модель “франкенмердж” будет содержать все 32 слоя из первой модели и 8 дополнительных слоев из второй. Таким образом, получится франкенмердж с 40 слоями и 8,99 миллиардами параметров. Стимулом для создания этой конфигурации послужила GML-Mistral-merged-v1.
Вы можете найти итоговую модель на хабе Hugging Face по ссылке.
Объединяйте модели
В этом разделе мы будем использовать mergekit для загрузки конфигурации слияния, ее запуска и загрузки полученной модели на хаб Hugging Face.
Прежде всего, установим mergekit непосредственно из исходника следующим образом:
!git clone https://github.com/cg123/mergekit.git
!cd mergekit && pip install -q -e .
В следующем блоке загружаем конфигурацию слияния в формате YAML. Также указываем имя объединенной модели для дальнейшего использования. Вы можете скопировать/вставить сюда любую конфигурацию из предыдущего раздела.
На этот раз будем использовать две разные модели: Marcoroni-7B-v3 и Mistral-7B-Merge-14-v0.1 и объединим их с помощью метода SLERP. Сохраняем конфигурацию в виде YAML-файла, который будет использоваться в качестве входных данных в команде слияния.
import yaml
MODEL_NAME = "Marcoro14-7B-slerp"
yaml_config = """
slices:
- sources:
- model: AIDC-ai-business/Marcoroni-7B-v3
layer_range: [0, 32]
- model: EmbeddedLLM/Mistral-7B-Merge-14-v0.1
layer_range: [0, 32]
merge_method: slerp
base_model: AIDC-ai-business/Marcoroni-7B-v3
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
"""
# Сохранение конфигурации в виде YAML-файла
with open('config.yaml', 'w', encoding="utf-8") as f:
f.write(yaml_config)
Запускаем команду слияния со следующими параметрами.
--copy-tokenizer: для копирования токенизатора из базовой модели.--allow-crimesи--out-shard-size: для разбиения моделей на более мелкие шарды, которые можно вычислить на процессоре с небольшим объемом оперативной памяти.--lazy-unpickle: для включения экспериментального ленивого распаковщика с целью уменьшения затрат памяти.
Кроме того, для некоторых моделей может потребоваться флаг --trust_remote_code (не относится к Mistral-7B).
Эта команда загрузит веса всех моделей, перечисленных в конфигурации слияния, и запустит выбранный метод слияния (занимает около 10 минут).
# Слияние моделей
!mergekit-yaml config.yaml merge --copy-tokenizer --allow-crimes --out-shard-size 1B --lazy-unpickl
Модель объединена и сохранена в каталоге `merge`. Перед загрузкой можно создать файл README со всей информацией, необходимой для воспроизводимости. Следующий блок кода определяет шаблон Jinja и автоматически заполняет его данными из конфигурации слияния.
!pip install -qU huggingface_hub
from huggingface_hub import ModelCard, ModelCardData
from jinja2 import Template
username = "mlabonne"
template_text = """
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
{%- for model in models %}
- {{ model }}
{%- endfor %}
---
# {{ model_name }}
{{ model_name }} is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
{%- for model in models %}
* [{{ model }}](https://huggingface.co/{{ model }})
{%- endfor %}
## ???? Configuration
```yaml
{{- yaml_config -}}
```
"""
# Создание объекта шаблона Jinja
jinja_template = Template(template_text.strip())
# Получение списка моделей из конфигурации
data = yaml.safe_load(yaml_config)
if "models" in data:
models = [data["models"][i]["model"] for i in range(len(data["models"])) if "parameters" in data["models"][i]]
elif "parameters" in data:
models = [data["slices"][0]["sources"][i]["model"] for i in range(len(data["slices"][0]["sources"]))]
elif "slices" in data:
models = [data["slices"][i]["sources"][0]["model"] for i in range(len(data["slices"]))]
else:
raise Exception("No models or slices found in yaml config")
# Заполнение шаблона
content = jinja_template.render(
model_name=MODEL_NAME,
models=models,
yaml_config=yaml_config,
username=username,
)
# Сохранение карты модели
card = ModelCard(content)
card.save('merge/README.md')
Теперь, когда у нас есть карта модели, можем передать всю папку на хаб.
from google.colab import userdata
from huggingface_hub import HfApi
username = "mlabonne"
# Определяется на вкладке "Secrets" в Google Colab
api = HfApi(token=userdata.get("HF_TOKEN"))
api.create_repo(
repo_id=f"{username}/{MODEL_NAME}",
repo_type="model"
)
api.upload_folder(
repo_id=f"{username}/{MODEL_NAME}",
folder_path="merge",
)
Модель теперь доступна на хабе Hugging Face по ссылке. В другом ноутбуке можем потестить модель на бесплатном GPU T4, используя следующий код:
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "mlabonne/Marcoro14-7B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
Мы задали вопрос “Что такое большая языковая модель?” и получили ответ:
Большая языковая модель — это тип системы ИИ, которая была обучена на огромных объемах текстовых данных. Она предназначена для понимания и генерации человекоподобного языка с целью составления прогнозов о том, какие слова или фразы могут быть следующими в предложении или документе. Эти модели используют сложные алгоритмы и архитектуры нейронных сетей, чтобы учиться на данных и улучшать производительность с течением времени. Среди известных крупных языковых моделей можно назвать GPT-3 от OpenAI и BERT от Google.
Выглядит неплохо, но нам нужна более комплексная оценка. Для такого рода моделей общего назначения существует несколько интересных бенчмарков.
- Chatbot Arena: составляет таблицу лидеров LLM на основе Elo, ориентируясь на результаты голосования людей.
- MT-bench (та же ссылка): использует GPT-4 в качестве оценщика ответов модели на множестве “многооборотных” вопросов.
- Набор бенчмарков NousResearch: объединяет четыре бенчмарка — AGIEval, GPT4ALL, TruthfulQA и Bigbench. Сам GPT4ALL включает HellaSwag, OpenBookQA, Winogrande, ARC-Easy, ARC-Challenge, BoolQ и PIQA.
- Open LLM Leaderboard: объединяет шесть бенчмарков — ARC, HellaSwag, MMLU, Winogrande, GSM8K и TruthfulQA.
К сожалению, мы не можем отправить модель на Chatbot Arena. Вместо этого я решил оценить ее с помощью бенчмарков Open LLM Leaderboard и NousResearch.
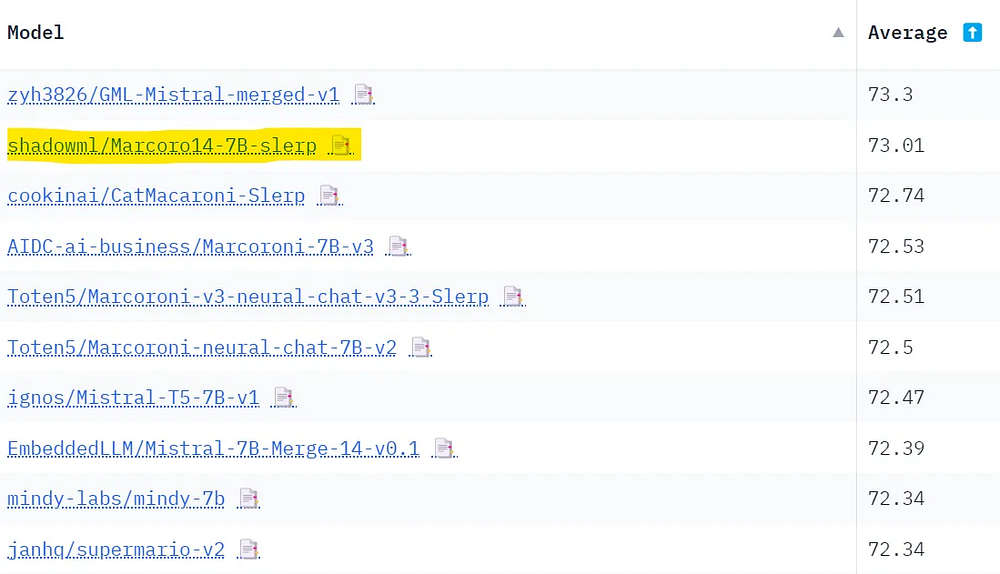
Я отправил модель на Open LLM Leaderboard (вкладка “Submit here!”). Как показано во введении, она заняла место лучшей модели с 7 миллиардами параметров в таблице лидеров. Вот все результаты:

Проблема с Open LLM Leaderboard заключается в том, что эти бенчмарки находятся в открытом доступе. Это значит, что люди могут обучать LLM на тестовых данных, чтобы получить лучшие результаты. Объединяя топовые модели, мы в то же время “загрязняем” результаты. Можно предположить, что Marcoro14–7B-slerp загрязнена, а некоторые модели, используемые в этом процессе слияния, обучались на тестовом наборе. Если хотите создать топовую модель без манипуляций с таблицей лидеров, рекомендую использовать для создания собственных слияний только не объединенные модели.
Вот почему не стоит полагаться лишь на OpenLLM Leaderboard. Для набора бенчмарков NousResearch я использовал LLM AutoEval для автоматического вычисления оценок с помощью простого ноутбука Colab. Вот результаты в сравнении с превосходной OpenHermes-2.5-Mistral-7B:

Мы получаем значительно лучшие результаты по сравнению с этой моделью по каждому бенчмарку. Обратите внимание: набор бенчмарков NousResearch имеет некоторые общие задачи с Open LLM Leaderboard (ARC-Challenge, TruthfulQA, HellaSwag и Winogrande). Насколько мне известно, Bigbench — единственный бенчмарк, который отличается на все 100%. Тем не менее одна из моделей, которую мы использовали в этом процессе слияния, могла быть обучена на Bigbench.
Заключение
В данной статье мы представили концепцию слияния LLM с помощью четырех различных методов. Мы подробно описали, как работают SLERP, TIES, DARE и passthrough, и привели примеры конфигураций. Наконец, запустили SLERP с библиотекой mergekit, чтобы создать Marcoro14–7B-slerp и загрузить ее на хаб Hugging Face. Мы получили отличные показатели производительности в двух наборах бенчмарков: Open LLM Leaderboard (лучшая модель с 7 миллиардами параметров) и NousResearch. Если хотите создавать слияния самостоятельно, рекомендую использовать мой автоматизированный ноутбук LazyMergekit.