Вы хотите избежать блокиро? ... Как избежать блокировки с помощью Python: 8 советов и приемов
Как избежать блокировки с помощью Python: 8 советов и приемов...
Вы хотите избежать блокировки при сборе данных из Интернета или выполнении других задач с помощью Python? Тогда вы попали на нужную страницу, поскольку в статье ниже рассматриваются основные методы обхода блокировок в Python.
Веб-автоматизация облегчает наши задачи в Интернете. Некоторые задачи даже невозможно выполнить без веб-автоматизации, особенно если они требуются в больших масштабах. Даже несмотря на важность веб-автоматизации для Интернета, веб-автоматизация в целом ненавистна большинству веб-сервисов. Ни один сайт не хочет получить доступ к автоматизации — ни для того, чтобы спарсить свои данные, ни для того, чтобы совершать покупки в автоматическом режиме. Если вы занимаетесь веб-парсингом или другими формами автоматизации, вы согласитесь со мной, что блокировки — это нормально, за исключением случаев, когда вы предпринимаете сознательные шаги, чтобы избежать их. К счастью для нас, вы действительно можете избежать блокировки. Если вы являетесь разработчиком Python и хотите избежать блокировок в Python, эта статья написана для вас. Важно знать, что вам нужно учесть некоторые моменты и использовать некоторые техники, чтобы успешно избежать блокировки, поскольку веб-сайты становятся все более умными в обнаружении действий, связанных с ботами. Одно вы должны знать наверняка: если вы знаете, как сайт обнаруживает действия бота, вы можете обойти проверки и сделать так, чтобы ваш бот выглядел как человек.
8 проверенных советов, как избежать блокировки с помощью Python
Python — это всего лишь один из языков программирования, используемых для разработки веб-парсеров. Однако на самом деле это один из популярных языков для разработки ботов в целом. Даже если вы не являетесь разработчиком Python, описанные здесь методы можно применить к выбранному вами языку программирования. Ниже приведены некоторые способы, которые помогут вам избежать блокировки при использовании Python.
1: Используйте вращающиеся прокси-серверы

Самый элементарный метод обхода блокировок при выполнении автоматизации в Интернете — использование прокси-серверов. Прокси-серверы — это серверы-посредники, которые предоставляют вам альтернативные IP-адреса. В случае их вращающихся аналогов вам предоставляется не просто один IP-адрес — присвоенный вам IP-адрес часто меняется. Частая смена IP-адреса очень важна, если вы хотите избежать блокировки. Оказывается, у каждого сайта есть лимит разрешения запросов на один IP-адрес. Если вы попытаетесь отправить больше запросов с одного и того же IP-адреса, вас, скорее всего, заблокируют. Этот лимит запросов не является общедоступным и варьируется в зависимости от сайта и задачи. Но одно мы знаем точно — частая смена IP поможет вам избежать блокировки из-за отправки слишком большого количества запросов с одного IP-адреса. Боты, по своей природе, отправляют слишком много запросов за короткий промежуток времени, и им нужны вращающиеся прокси, чтобы пробиться через антиспам-системы сайтов. Мы рекомендуем вам использовать высококачественную прокси-сеть с автоматической ротацией IP-адресов. Bright Data и Smartproxy являются одними из наиболее рекомендуемых прокси-сетей для жилых домов с огромными IP-пулами, хорошей поддержкой местоположения и совершенно необнаруживаемыми.
- BrightData (Luminati Proxy) — лучший прокси в целом <Экспертное мнение № 1 для парсинга>.
- Smartproxy — быстрый жилой прокси-пул <Лучший выбор стоимости>
- Soax — Лучший мобильный прокси-пул <Самый чистый для автоматизации Instagram>
Для некоторых задач жилые прокси не подойдут — вам понадобятся мобильные прокси. Вы можете приобрести вращающиеся мобильные прокси у Bright Data. Soax — еще один поставщик работающих вращающихся мобильных прокси. Использование прокси в коде Python очень просто. Ниже приведен пример кода с использованием сторонней библиотеки запросов.
импортные запросы
прокси = {
‘http’: ‘http://proxy.example.com:8080’,
‘https’: ‘http://secureproxy.example.com:8090’,
}
url = ‘http://mywebsite.com/example’
response = requests.post(url, proxies=proxies)
2: Используйте программу Captcha Solver

Веб-сайты с каждым днем становятся все умнее, и простого использования прокси недостаточно. Даже с прокси они могут угадать, являетесь ли вы ботом или нет. Некоторые из популярных форм блокировок, с которыми вы столкнетесь как разработчик ботов, — это капчи. И когда вам попадется один из них, если вы не сможете его решить, ваша задача на этом закончится. Справиться с этим просто — воспользуйтесь решателем капчи. С помощью решателей капчи вы сможете решать возникающие капчи, что позволит вам беспрепятственно продолжить выполнение задачи автоматизации. Когда дело доходит до решения капчи, на рынке существует множество сервисов для решения капчи. 2Captcha и DeathByCaptcha являются одними из популярных вариантов, доступных для вас. Хотя некоторые капчи могут быть решены с помощью искусственного интеллекта, большинство капч в настоящее время требуют участия людей, и поэтому эти сервисы по решению капч нанимают людей из стран третьего мира для решения капч. По этой причине не надейтесь получить бесплатные решатели капчи, которые работают, особенно когда имеете дело со сложными капчами, которые не могут быть решены с помощью ИИ.
3: Установите пользовательские агенты пользователя и другие соответствующие заголовки — и чередуйте их
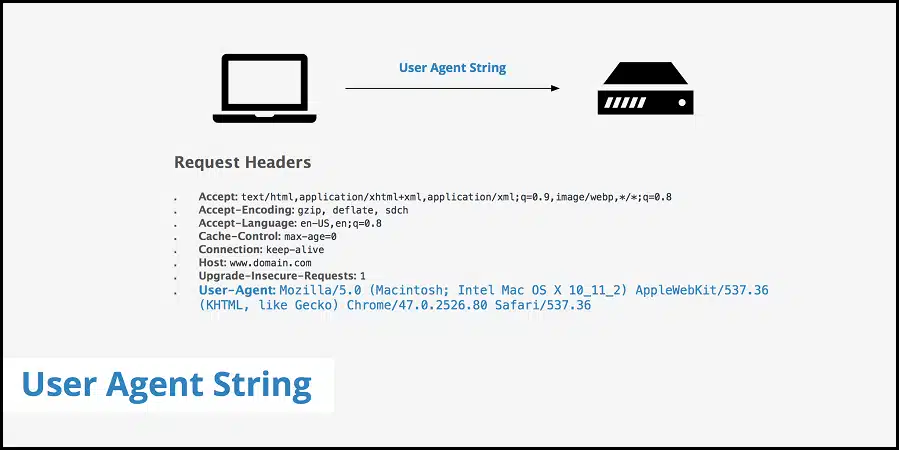
Один из самых простых способов обнаружения ботов веб-службами — по их пользовательским агентам и другим соответствующим заголовкам. Python — популярный язык программирования для веб-парсинга, и веб-сайты знают заголовки по умолчанию, установленные Python и его популярными библиотеками HTTP. Возьмем, к примеру, библиотеку requests, использующую «python-requests/2.25» в качестве строки агента пользователя по умолчанию. Это сразу же выдаст вас. В прошлом я пытался спарсить Amazon без установки пользовательского заголовка user agent с помощью Python, и был заблокирован. После установки агента пользователя для моего браузера Chrome запрос прошел. Агент пользователя предназначен для идентификации клиента. Поскольку веб-сайты разрешают доступ только обычным пользователям, лучше использовать агент пользователя популярных браузеров. Вот веб-страница, на которой можно найти подробную информацию об агентах пользователей популярных браузеров. Также важно знать, что помимо агента пользователя существуют и другие соответствующие заголовки, которые необходимо установить. Они различаются в зависимости от веб-сайтов. Используйте инструменты «Сеть» в Инструментах разработчика вашего браузера, чтобы проверить необходимые заголовки, установленные вашим браузером при отправке запроса на целевой сайт. Некоторые из популярных заголовков запроса включают «Accept», «Accept-Encoding» и «Accept-Language». Заголовки запросов, которые являются уникальными и обязательными для вашего целевого сайта, станут вам известны, если вы воспользуетесь инструментом разработчика. Просто установить пользовательский агент недостаточно. Вам также необходимо повернуть агент пользователя. Ниже приведен код, как установить строку агента пользователя в Python.
импортные запросы
headers = {«User-Agent»: «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36»}
response = requests.get(«http://www.kite.com», headers=headers)
4: Используйте безголовый браузер

Еще один способ избежать блокировки — использование безголовых браузеров. Безголовые браузеры — это программное обеспечение, которое действует как настоящие браузеры, но без пользовательского интерфейса браузера (UI). Они в основном используются для автоматизированного тестирования и автоматизации веб-процессов в целом. В прошлом единственная причина, по которой вам нужно было использовать безголовые браузеры для веб-парсинга или других форм автоматизации, заключалась в том, что целевой веб-сайт зависит от JavaScript для отображения своего содержимого. В настоящее время веб-сайты используют JavaScript для сбора различных данных, которые они используют для создания отпечатков браузера или простого мониторинга поведения. Если вы используете обычные библиотеки HTTP, такие как библиотека requests HTTP для Python, ваш целевой сайт может определить, что вы используете бота, а не браузер. Для разработчиков Python, Selenium — это инструмент для работы. Selenium автоматизирует веб-браузеры так, чтобы ваш бот вел себя как настоящий браузер. Он может вызывать такие события, как клики, прокрутки и всевозможные события. Это даже уменьшит количество капч, так как ваши действия будут реальными. Единственная серьезная проблема, связанная с использованием Selenium или любого другого инструмента для автоматизации браузеров, заключается в том, что это медленнее, чем использование обычных HTTP-библиотек.
5: Установите случайные задержки между запросами
Одна из причин, по которой вас легко заблокировать, заключается в том, что ваш бот отправляет слишком много веб-запросов за короткий промежуток времени. Если вы вошли в учетную запись на сайте, то знайте, что прокси вам не помогут — вы известны. Вместо того чтобы пытаться использовать прокси, вы можете ограничить скорость отправки запросов. Как уже говорилось, большинство сайтов блокируют вас, если вы превышаете лимит запросов. Единственный серьезный способ справиться с этим — установить задержки в коде. В python вы можете использовать метод «sleep» в классе «time» для установки задержек между запросами. Помимо того, что вы видите задержки, лучше сделать их случайными, так как отправка запросов через одинаковые промежутки времени также выдаст вас как бота.
6: Избегайте Honeypots

Веб-сайты становятся все более хитрыми в своих методах борьбы с парсерами. Одним из способов обнаружения веб-парсера является установка медовых ловушек. Медовые ловушки — это, по сути, добавление невидимых ссылок на страницу. Ссылка маскируется таким образом, что обычные пользователи Интернета не видят ее. Для отображения ссылки в атрибуте CSS устанавливается значение none {display:none} или видимость hidden {visibility:hidden}. При таких значениях атрибутов ссылки не видны для глаз, но автоматические боты их видят. После посещения такого URL-адреса веб-сайт будет блокировать дальнейшие запросы. Иногда они могут быть еще умнее. Вместо того чтобы использовать вышеупомянутые атрибуты, они просто устанавливают кулер URL на белый, если кулер фона белый. Таким образом, веб-парсеры, стремящиеся избежать URL-адресов, у которых значение display или visibility установлено так, чтобы сделать их невидимыми, все равно попадут в ловушку. По этой причине следует программно получить все URL-адреса, подлежащие краулингу, и убедиться, что они не имеют атрибутов или настроек CSS, которые сделают их скрытыми. Чтобы избежать обнаружения и блокировки, следует избегать любых обнаруженных URL.
7: Парсинг кэш Google вместо этого

Иногда целевой сайт может оказаться труднораскалываемым орешком. Если вы не хотите возиться с хлопотами, пытаясь избежать блокировки, вы можете сделать сбор из индекса Google. К счастью для нас, Google хранит кэш страниц, доступных в его индексе. И хорошая новость заключается в том, что он не так защищен, как сама платформа Google Search. Вы можете брать информацию из этого индекса и избавить себя от головной боли, связанной с системами защиты от спама. Чтобы сделать выборку из кэша Google, используйте этот URL: «http://webcache.googleusercontent.com/search?q=cache:YOUR_URL». Замените YOUR_URL на URL вашей целевой страницы. Однако важно знать, что не все страницы доступны в кэше Google. Любая веб-страница, недоступная в Google, например, страницы, защищенные паролем, не может быть найдена в Google Cache. Также важно знать, что некоторые веб-сайты, даже если они доступны в Google, запрещают Google кэшировать свои страницы для публичного доступа. Вопрос свежести также необходимо учитывать. Если данные на странице часто меняются, кэш Google в этом случае бесполезен — а для непопулярных сайтов это еще хуже из-за больших задержек между просмотрами.
8: Используйте API для парсинга

Последним средством избежать блокировки является использование API парсера. API парсер — это REST API, которые помогают вам извлекать данные с веб-сайтов, не сталкиваясь с проблемами блокировки. Большинство API для парсинга поддерживают управление прокси, безголовые браузеры и капчи. Некоторые даже поставляются с парсерами, чтобы облегчить извлечение данных. И еще один плюс API-парсинга в том, что вы платите только за успешные запросы — это заставляет их больше стремиться к предоставлению данных, так как только в этом случае они зарабатывают деньги. Используя API, вы можете сосредоточиться только на данных, а не на блоках. Это также поможет вам не беспокоиться об управлении веб-парсерами и изменениями на сайте. В настоящее время ScraperAPI, ScrapingBee и WebScraperAPI являются лучшими API для парсинга. Они также доступны по цене.
Топ-3 лучших API для веб-парсинга
- Apify Proxy
- ScraperAPI
- ScrapingBee
Заключение
Описанные выше методы — это одни из лучших методов, которые вы можете использовать, чтобы избежать блокировки при автоматизации задач в Python. Одна хорошая особенность описанных выше методов заключается в том, что они не являются уникальными для Python. Методы, позволяющие избежать блокировки при выполнении веб-парсинга или других форм автоматизации, не являются уникальными для какого-либо языка программирования. Вы можете применять их и в других языках.
