Внутренняя платформа МО Bigeye: цели и методы создания.
Машинное обучение на платформе Bigeyeизбавляет инженеров и специалистов по обработке данных от необходимости вручную настраивать критерии оповещений. Оно существенно экономит время, ведь получение показателей качества данных исключает постоянную рекалибровку при их введении или изменении.
Благодаря столь впечатляющему функционалу, управляемому МО, интеллект минималистической платформы Bigeye теперь удвоился. Сегодня это обеспечи?
Внутренняя платформа МО Bigeye: цели и методы создания...
Машинное обучение на платформе Bigeyeизбавляет инженеров и специалистов по обработке данных от необходимости вручную настраивать критерии оповещений. Оно существенно экономит время, ведь получение показателей качества данных исключает постоянную рекалибровку при их введении или изменении.
Благодаря столь впечатляющему функционалу, управляемому МО, интеллект минималистической платформы Bigeye теперь удвоился. Сегодня это обеспечивает ускоренное обучение моделей, а в дальнейшем позволит Bigeye продолжать набирать интеллектуальную мощь.
Замедление машинного обучения
Bigeye выявляет показатели качества данных, подлежащих отслеживанию, а затем использует МО для прогнозирования временных рядов, автоматически определяя выход этих показателей за пределы автоматических порогов. Создание микросервиса, отвечающего за обслуживание автопорогов, было обусловлено замедлением обучения моделей примерно на 10 секунд.
Осуществление МО в режиме реального времени в традиционной блокированной конечной точке API было невозможно по следующим причинам.
- Модели нуждаются в переобучении по мере сбора данных.
- Недопустимо задерживать потоки в запрашивающей службе, которая запускает запланированные показатели с ожиданием ответа в течение 10 секунд.
- Клиенты могут запускать показатели по требованию из пользовательского интерфейса. Мало кому нравится смотреть на спиннер в течение 10+ секунд.
С учетом этих проблем, было принято решение предварительно обучать модели в автономном режиме. Предстоящий апгрейд Bigeye потребовал включения еще нескольких технических требований.
- Создание сервиса обучения моделей, отдельного от службы автопороговых прогнозов. Потребность в обучающем сервисе, способном независимо масштабироваться, продиктована расширением внедрения программного продукта.
- Обеспечение такого функционала платформы, который позволит в дальнейшем встраивать в нее новые функции МО.
- Отказ от сторонних сервисов, таких как AWS Sagemaker, и разработка собственного аналогичного решения. Это гарантирует обслуживание Bigeye различных сред развертывания (как SaaS, так и локальных клиентов).
Создание масштабируемой облачной платформы МО внутри Bigeye
В любой нетривиальной вычислительной среде критически важно взаимодействие между интерсервисами и интеркомпонентами. Чрезвычайно полезным в этом плане является составление схем интерфейсов. Protobuf и Thrift — одни из популярных инструментов сериализации данных.
В Bigeye был использован протокол Protobuf, который позволяет систематизировать объекты в одном месте и компилировать код на нескольких языках (Java, Python, Javascript). Это обеспечивает возможность повторного использования объектов во всех сервисах Bigeye.
Для описания компонентов платформы полезно использовать простой иллюстративный пример. Предположим, что мы хотим построить модель, которая предсказывает погоду в Сан-Франциско.
Компоненты и интерфейсы
В дизайн платформы входят три ключевых компонента: поставщики функций, модели и служба оркестратора. При этом поставщики функций и модели должны соответствовать определенным интерфейсам, чтобы обеспечить адаптацию новых моделей к платформе.
Поставщики функций
Чтобы функции были каноническими и многократно используемыми в разных моделях (а, возможно, и во всей кодовой базе), была разработана концепция “поставщиков функций”. Они должны использоваться для получения данных, необходимых в обучении моделей.
Так, входными данными для модели погоды может быть информация о погоде в Сан-Франциско за последние 30 дней. В этом случае поставщик функций будет представлять собой фрагмент кода, который извлекает эти данные и организует их в форму, используемую моделью.
Все функции, а также входные данные для поставщиков функций должны быть определены в Protobuf, что позволяет легко создавать запросы на обучение. Определение самих функций в Protobuf также позволяет использовать их в моделях (и в любом другом месте кода).
Наконец, все поставщики функций должны реализовать метод provide(), который использует входные данные поставщика функций и возвращает функцию в качестве выходных данных. Поставщики функций теоретически могут извлекать данные из любого места — API REST, базы данных, деконструктора входных данных и пр. — до тех пор, пока они соответствуют интерфейсу и обеспечивают возврат корректного объекта.
Модели
Модели МО выполняют сложные интеллектуальные задачи на платформе Bigeye. Чтобы внедрять инновации с минимальными отклонениями, команда исследователей данных применила максимальное количество разрешений к моделям, но при этом стандартизировала их, чтобы обеспечить возможность новых разработок.
Снова обратимся к нашей модели погоды. Она будет представлять собой код, который получает данные за 30 дней от поставщика функций и обучает модель МО для прогнозирования будущих погодных условий.
Единственное требование к моделям МО сегодня заключается в том, чтобы они реализовывали метод train() и использовали в обучении функции, определенные Protobuf. Этот метод train() должен хранить состояние модели в самом классе для дальнейшего использования во время выполнения.
Служба оркестратора
Третья часть дизайна платформы — сервис оркестратора. Он был спроектирован таким образом, чтобы предоставлять услуги по принятому шаблону:
- принятие запроса на обучение модели;
- получение задачи для модели с помощью поставщиков функций;
- обучение модели;
- сохранение обученной модели для повторного использования службой, оценивающей время выполнения функций.
Чтобы оказать помощь в поиске корректных моделей и поставщиков функций, оркестратор имеет два реестра.
- Первый — это сопоставление типов моделей с кодом модели и функциями, необходимыми для нее. В примере выше это будет модель погоды с данными о погоде за последние 30 дней.
- Второй — это карта от функций к поставщикам функций (например, от 30 дней данных о погоде до кода, который фактически извлекает данные). Запросы поступают из очереди сообщений, что позволяет масштабировать количество машин-оркестраторов, чтобы не отставать от бизнес-спроса.
Внедрение новой модели
Сервис МО обеспечивает простоту и гибкость использования. Новую модель можно подключить, не касаясь кода оркестратора. Прежде всего, модель нужно описать и внести в реестр. Если все необходимые для нее функции уже имеют поставщиков, то больше ничего делать не придется — оркестратор может начать обработку запросов на обучение. Если потребуются новые функции, то нужно описать и зарегистрировать новых поставщиков функций. После этого платформа может начать обработку запросов на обучение.
Процесс адаптации новой модели можно визуализировать следующим образом.
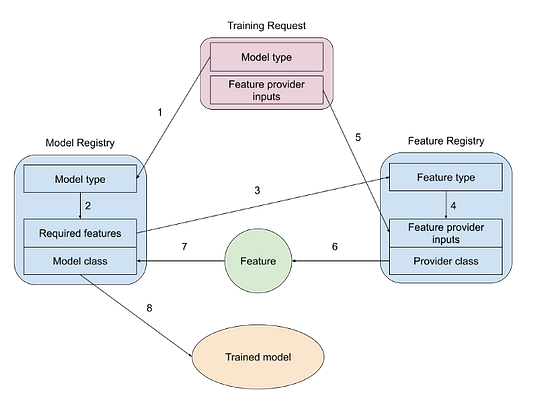
- Поступление запроса на обучение, который включает идентификатор типа модели и входные данные для поставщиков функций.
- Запуск реестра моделей для поиска необходимых функций, а также класса модели из типа модели.
- Использование необходимых функций из реестра моделей в качестве входных данных для реестра функций.
- Запуск реестра функций для поиска необходимых входных данных функций, а также классов поставщиков из типов функций.
- Извлечение входных данных поставщика функций из запроса на обучение.
- Использование класса поставщика для предоставления функции для модели.
- Ввод функции в класс модели, который был просмотрен из типа модели в запросе на обучение.
- Обучение модели и кэширование для использования во время выполнения.