Система инженерии данных «от и до» с Kafka, Spark, Airflow, Postgres и Docker. Часть 1.
Первая часть проекта предназначена для дата-инженеров, дата-сайентистов и специалистов по машинному обучению, желающих пополнить багаж знаний обо всем процессе обработки данных, оптимально создавать и расширять модели машинного обучения, обеспечивая их эффективную работу в практических условиях.
Мы построим конвейер данных с Kafka для потоковой их передачи из API, с Airflow для оркестрации, со Spark для преобразования данных и PostgreSQL для их
Система инженерии данных «от и до» с Kafka, Spark, Airflow, Postgres и Docker. Часть 1...
Первая часть проекта предназначена для дата-инженеров, дата-сайентистов и специалистов по машинному обучению, желающих пополнить багаж знаний обо всем процессе обработки данных, оптимально создавать и расширять модели машинного обучения, обеспечивая их эффективную работу в практических условиях.
Мы построим конвейер данных с Kafka для потоковой их передачи из API, с Airflow для оркестрации, со Spark для преобразования данных и PostgreSQL для их хранения. Эти инструменты настраиваются и запускаются с помощью Docker, сделаем акцент на практическом их применении ― теории в интернете и так предостаточно.
Во второй части, чтобы взаимодействовать с PostgreSQL и другими внешними БД, разработаем приложение с языковой моделью, создадим агенты LangChain. Для таких приложений и начала работы с системами данных подобное структурирование проекта идеально.
Обзор
Разберем конвейер подробно:
- Сначала выполняется потоковая передача данных из API в тему Kafka.
- Обработка: затем данные из темы Kafka поступают в задание Spark и передаются в PostgreSQL.
- Планирование: потоковая задача и задание Spark оркестрируются с помощью Airflow. Несмотря на то, что API в реальном сценарии постоянно прослушивается отправителем Kafka, мы запланируем ежедневное выполнение потоковой задачи Kafka. По завершении потоковой передачи данные обрабатываются в задании Spark, подготавливаясь к использованию в приложении с большими языковыми моделями.
Все эти инструменты создаются и запускаются с помощью docker-compose:

Переходим к техническим деталям.
Локальная настройка
Сначала клонируем репозиторий Github на локальном компьютере:
git clone https://github.com/HamzaG737/data-engineering-project.git
Вот общая структура проекта:
├── LICENSE
├── README.md
├── airflow
│ ├── Dockerfile
│ ├── __init__.py
│ └── dags
│ ├── __init__.py
│ └── dag_kafka_spark.py
├── data
│ └── last_processed.json
├── docker-compose-airflow.yaml
├── docker-compose.yml
├── kafka
├── requirements.txt
├── spark
│ └── Dockerfile
└── src
├── __init__.py
├── constants.py
├── kafka_client
│ ├── __init__.py
│ └── kafka_stream_data.py
└── spark_pgsql
└── spark_streaming.py
- В каталоге
airflowсодержится пользовательский Dockerfile для настройки airflow и каталогdagsдля создания и планирования задач. - В каталоге
dataнаходится важный для потоковой задачи Kafka файл last_processed.json. Подробнее о нем ― ниже в описании Kafka. - В файле
docker-compose-airflow.yamlопределяются все службы, необходимые для запуска airflow. - В файле
docker-compose.yamlуказываются службы Kafka и docker-proxy, необходимый для выполнения заданий Spark с помощью docker-operator в Airflow. Подробнее об этом ― ниже. - В каталоге
sparkсодержится пользовательский Dockerfile для настройки Spark. - В
srcнаходятся модули Python для запуска приложения.
Настройка локальной среды разработки начинается с установки psycopg2-binary, единственного необходимого пакета Python. Не ограничиваясь только им, устанавливаем все пакеты файла requirements.txt:
pip install -r requirements.txt
Рассмотрим проект подробнее.
Об API
API ― это RappelConso от французских общедоступных сервисов, через него предоставляется доступ к данным об объявленных специалистами отозванных из продажи во Франции товаров. Данные на французском языке, в них изначально содержится 31 столбец, или поле. Вот самые важные:
- reference_fiche (справочный перечень): уникальный идентификатор отозванного продукта, это будет первичный ключ Postgres;
- categorie_de_produit (категория товара): еда, электроприборы, инструменты, транспортные средства и т. д.;
- sous_categorie_de_produit (подкатегория товара): для категории еды, например это мясо, молочные продукты, крупы;
- motif_de_rappel (причина изъятия): одно из важнейших полей;
- date_de_publication: дата опубликования;
- risques_encourus_par_le_consommateur: риски потребителя при использовании продукта;
- имеются еще поля с различными ссылками на изображение продукта, список поставщиков и т. д.
Посмотреть примеры и вручную запросить записи набора данных можно здесь.
Важные изменения:
- Такие столбцы, как
ndeg_de_versionиrappelguid, бывшие частью системы контроля версий и ставшие ненужными проекту, удалены. - Для удобства столбцы, связанные с рисками потребителя ―
risques_encourus_par_le_consommateurиdescription_complementaire_du_risque, ― объединены. - Столбец
date_debut_fin_de_commercialisation, в котором указывается маркетинговый период, разделен на два столбца: так проще делать запросы о начале или окончании маркетинговых мероприятий по продукту. - За исключением столбцов со ссылками, справочными номерами и датами, везде убраны надбуквенные знаки: с такими символами у текстовых редакторов случаются проблемы.
Подробнее об этих изменениях ― в скриптах трансформации. Обновленный список столбцов доступен здесь в DB_FIELDS.
Потоковая передача Kafka
Чтобы не отправлять из API все данные при каждом запуске потоковой задачи, определяем локальный json-файл с прошлой датой опубликования последней потоковой передачи. Эта дата будет начальной для новой потоковой задачи.
Предположим, дата опубликования последнего отозванного продукта ― 22 ноября 2023 года. Если до этой даты информация обо всех отозванных продуктах уже сохранена в Postgres, выполняем потоковую передачу данных с 22 ноября. Дата дублируется на случай, если данные от 22 ноября обработаны не все.
Файл сохраняется в ./data/last_processed.json в таком формате:
{last_processed:"2023-11-22"} По умолчанию файл ― пустой json, то есть первой потоковой задачей обработаются все ~10 000 записей API.
В условиях продакшена такой подход сохранения в локальном файле последней обработанной даты нежизнеспособен в отличие от других ― с внешней БД или службой хранения объектов.
Вот код для потоковой передачи Kafka: по сути, это запрос данных из API, выполнение преобразований, удаление потенциальных дублей, обновление последней даты опубликования и предоставление данных отправителем Kafka.
Следующий этап ― запуск службы Kafka, определенной в docker-compose ниже:
version: '3'
services:
kafka:
image: 'bitnami/kafka:latest'
ports:
- '9094:9094'
networks:
- airflow-kafka
environment:
- KAFKA_CFG_NODE_ID=0
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://localhost:9094
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
volumes:
- ./kafka:/bitnami/kafka
kafka-ui:
container_name: kafka-ui-1
image: provectuslabs/kafka-ui:latest
ports:
- 8800:8080
depends_on:
- kafka
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: PLAINTEXT://kafka:9092
DYNAMIC_CONFIG_ENABLED: 'true'
networks:
- airflow-kafka
networks:
airflow-kafka:
external: true
Ключевые моменты из этого файла:
- Службой kafka используется базовый образ
bitnami/kafka. - Она настраивается всего одним брокером: для небольшого проекта этого достаточно. Брокером Kafka сообщения от отправителей ― источников данных получаются, сохраняются и доставляются получателям ― приемникам или конечными пользователям данных. Брокером прослушивается порт 9092 для внутреннего обмена данными в кластере и порт 9094 для внешнего обмена данными, благодаря чему клиенты вне сети Docker подключаются к брокеру Kafka.
- В volumes локальный каталог
kafkaсопоставляется с каталогом контейнера Docker/bitnami/kafka, так обеспечивается сохраняемость данных и возможная проверка данных Kafka из хост-системы. - Мы настроили службу kafka-ui, которой используется Docker-образ
provectuslabs/kafka-ui:latest. Этот пользовательский интерфейс взаимодействия с кластером Kafka особенно полезен для отслеживания и контроля тем и сообщений Kafka. - Взаимодействие kafka и airflow, запускаемым как внешняя служба, обеспечивается внешней сетью airflow-kafka.
Прежде чем запускать службу Kafka, создадим сеть airflow-kafka:
docker network create airflow-kafka
Теперь запускаем службу Kafka:
docker-compose up
После запуска служб переходим в kafka-ui через http://localhost:8800/:
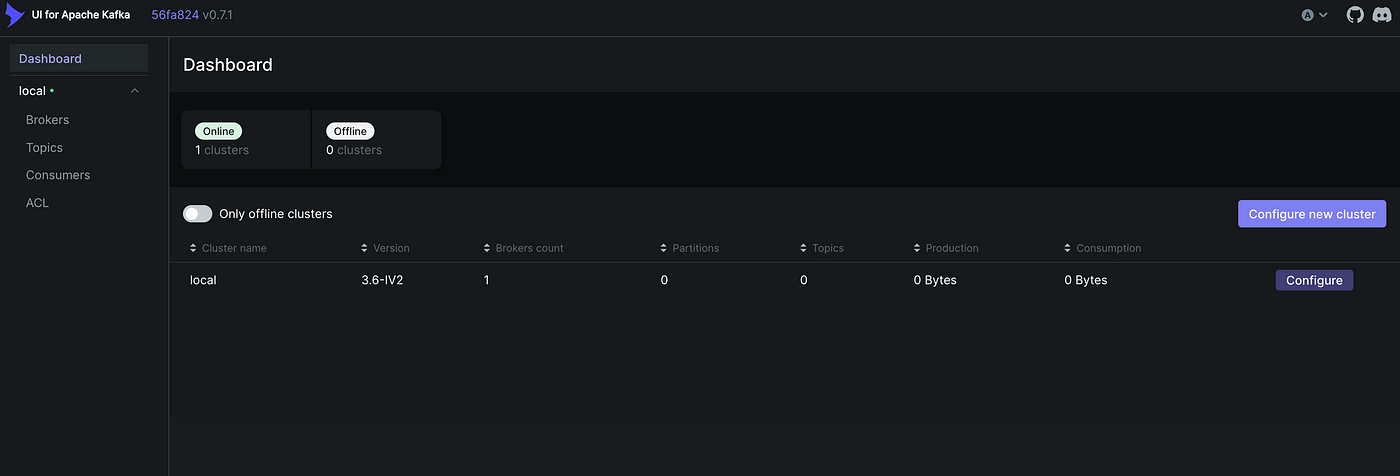
Далее создадим тему для сообщений API. Нажимаем слева Topics («Темы»), затем слева вверху добавляем тему rappel_conso и задаем коэффициент репликации 1, так как брокер только один. Количество разделов задаем 1, так как поток-получатель тоже только один, никакого параллелизма. Наконец, задаем небольшое время хранения данных, например час: задание Spark запустится сразу после потоковой задачи Kafka, поэтому долго хранить данные в теме Kafka не нужно.
Настройка Postgres
Прежде чем настраивать конфигурации Spark и Airflow, создадим БД Postgres для постоянного хранения данных API. Для этого воспользуемся pgadmin 4.
Чтобы установить Postgres и pgadmin, получаем здесь соответствующие операционной системе пакеты. Затем при установке Postgres задаем пароль, который позже понадобится для подключения к БД из среды Spark. Также оставляем порт 5432.
После установки запускаем pgadmin:
Поскольку у создаваемой нами таблицы много столбцов, добавляем их скриптом с помощью psycopg2, адаптера базы данных PostgreSQL для Python.
Запускаем скрипт:
python scripts/create_table.py
В скрипте сохраняем пароль Postgres как переменную окружения POSTGRES_PASSWORD. Чтобы использовать другой метод доступа к паролю, вносим в скрипт соответствующие изменения.
Настройка Spark
Настроив Postgres, подробно рассмотрим задание Spark. Цель ― потоковая передача данных из темы Kafka rappel_conso в таблицу Postgres rappel_conso_table:
from pyspark.sql import SparkSession
from pyspark.sql.types import (
StructType,
StructField,
StringType,
)
from pyspark.sql.functions import from_json, col
from src.constants import POSTGRES_URL, POSTGRES_PROPERTIES, DB_FIELDS
import logging
logging.basicConfig(
level=logging.INFO, format="%(asctime)s:%(funcName)s:%(levelname)s:%(message)s"
)
def create_spark_session() -> SparkSession:
spark = (
SparkSession.builder.appName("PostgreSQL Connection with PySpark")
.config(
"spark.jars.packages",
"org.postgresql:postgresql:42.5.4,org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0",
)
.getOrCreate()
)
logging.info("Spark session created successfully")
return spark
def create_initial_dataframe(spark_session):
"""
Reads the streaming data and creates the initial dataframe accordingly.
"""
try:
# Получает потоковые данные из темы «random_names»
df = (
spark_session.readStream.format("kafka")
.option("kafka.bootstrap.servers", "kafka:9092")
.option("subscribe", "rappel_conso")
.option("startingOffsets", "earliest")
.load()
)
logging.info("Initial dataframe created successfully")
except Exception as e:
logging.warning(f"Initial dataframe couldn't be created due to exception: {e}")
raise
return df
def create_final_dataframe(df):
"""
Modifies the initial dataframe, and creates the final dataframe.
"""
schema = StructType(
[StructField(field_name, StringType(), True) for field_name in DB_FIELDS]
)
df_out = (
df.selectExpr("CAST(value AS STRING)")
.select(from_json(col("value"), schema).alias("data"))
.select("data.*")
)
return df_out
def start_streaming(df_parsed, spark):
"""
Starts the streaming to table spark_streaming.rappel_conso in postgres
"""
# Считываем из PostgreSQL имеющиеся данные
existing_data_df = spark.read.jdbc(
POSTGRES_URL, "rappel_conso", properties=POSTGRES_PROPERTIES
)
unique_column = "reference_fiche"
logging.info("Start streaming ...")
query = df_parsed.writeStream.foreachBatch(
lambda batch_df, _: (
batch_df.join(
existing_data_df, batch_df[unique_column] == existing_data_df[unique_column], "leftanti"
)
.write.jdbc(
POSTGRES_URL, "rappel_conso", "append", properties=POSTGRES_PROPERTIES
)
)
).trigger(once=True) \
.start()
return query.awaitTermination()
def write_to_postgres():
spark = create_spark_session()
df = create_initial_dataframe(spark)
df_final = create_final_dataframe(df)
start_streaming(df_final, spark=spark)
if __name__ == "__main__":
write_to_postgres()
Разберем ключевые моменты и функционал задания Spark:
- Сначала создается сессия Spark:
def create_spark_session() -> SparkSession:
spark = (
SparkSession.builder.appName("PostgreSQL Connection with PySpark")
.config(
"spark.jars.packages",
"org.postgresql:postgresql:42.5.4,org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0",
)
.getOrCreate()
)
logging.info("Spark session created successfully")
return spark
2. В функции create_initial_dataframe с помощью структурированной потоковой передачи Spark из темы Kafka принимаются потоковые данные:
def create_initial_dataframe(spark_session):
"""
Reads the streaming data and creates the initial dataframe accordingly.
"""
try:
# Получает потоковые данные из темы «random_names»
df = (
spark_session.readStream.format("kafka")
.option("kafka.bootstrap.servers", "kafka:9092")
.option("subscribe", "rappel_conso")
.option("startingOffsets", "earliest")
.load()
)
logging.info("Initial dataframe created successfully")
except Exception as e:
logging.warning(f"Initial dataframe couldn't be created due to exception: {e}")
raise
return df
3. Полученные данные преобразуются с помощью create_final_dataframe, к входящим данным JSON применяется схема, определяемая столбцами DB_FIELDS, так данные структурируются и подготавливаются к последующей обработке:
def create_final_dataframe(df):
"""
Modifies the initial dataframe, and creates the final dataframe.
"""
schema = StructType(
[StructField(field_name, StringType(), True) for field_name in DB_FIELDS]
)
df_out = (
df.selectExpr("CAST(value AS STRING)")
.select(from_json(col("value"), schema).alias("data"))
.select("data.*")
)
return df_out
4. Функцией start_streaming имеющиеся данные считываются из базы данных, сравниваются с входящим потоком, добавляются новые записи:
def start_streaming(df_parsed, spark):
"""
Starts the streaming to table spark_streaming.rappel_conso in postgres
"""
# Считываем из PostgreSQL имеющиеся данные
existing_data_df = spark.read.jdbc(
POSTGRES_URL, "rappel_conso", properties=POSTGRES_PROPERTIES
)
unique_column = "reference_fiche"
logging.info("Start streaming ...")
query = df_parsed.writeStream.foreachBatch(
lambda batch_df, _: (
batch_df.join(
existing_data_df, batch_df[unique_column] == existing_data_df[unique_column], "leftanti"
)
.write.jdbc(
POSTGRES_URL, "rappel_conso", "append", properties=POSTGRES_PROPERTIES
)
)
).trigger(once=True) \
.start()
return query.awaitTermination()
Полный код для задания Spark, которое мы запустим позже с помощью DockerOperator, находится в файле src/spark_pgsql/spark_streaming.py.
Сначала создадим образ Docker. Вот Dockerfile:
FROM bitnami/spark:latest
WORKDIR /opt/bitnami/spark
RUN pip install py4j
COPY ./src/spark_pgsql/spark_streaming.py ./spark_streaming.py
COPY ./src/constants.py ./src/constants.py
ENV POSTGRES_DOCKER_USER=host.docker.internal
ARG POSTGRES_PASSWORD
ENV POSTGRES_PASSWORD=$POSTGRES_PASSWORD
Начинаем с базового образа bitnami/spark, это готовый образ Spark. Затем устанавливаем py4j, инструмент для работы Spark с Python.
Переменные окружения POSTGRES_DOCKER_USER и POSTGRES_PASSWORD настроены для подключения к PostgreSQL. Поскольку база данных находится в хост-машине, в качестве пользователя задействуем host.docker.internal. Так у контейнера Docker будет доступ к службам на хосте, в данном случае доступ к PostgreSQL. Пароль для PostgreSQL передается в аргументе сборки, он не жестко задан в образе.
Важно: такой подход, особенно передача пароля БД во время сборки, небезопасен для использования в продакшене. Это чревато раскрытием конфиденциальной информации. В таких случаях следует подумать о более безопасных методах, например Docker BuildKit.
Создадим образ Docker для Spark:
docker build -f spark/Dockerfile -t rappel-conso/spark:latest --build-arg POSTGRES_PASSWORD=$POSTGRES_PASSWORD .
В этом образе rappel-conso/spark:latest имеется все необходимое для запуска задания Spark и его выполнения с DockerOperator. $POSTGRES_PASSWORD заменяем фактическим паролем PostgreSQL.
Airflow
В конвейере данных Apache Airflow ― инструмент оркестрации, которым планируется и контролируется рабочий процесс задач, обеспечивается их выполнение в определенном порядке и условиях. В нашей системе при помощи Airflow автоматизируется поток данных от потоковой передачи с Kafka до обработки со Spark.
Airflow DAG
Рассмотрим направленный ациклический граф DAG, которым описываются последовательность и зависимости задач для контроля Airflow за их выполнением:
start_date = datetime.today() - timedelta(days=1)
default_args = {
"owner": "airflow",
"start_date": start_date,
"retries": 1, # количество повторов до провала задачи
"retry_delay": timedelta(seconds=5),
}
with DAG(
dag_id="kafka_spark_dag",
default_args=default_args,
schedule_interval=timedelta(days=1),
catchup=False,
) as dag:
kafka_stream_task = PythonOperator(
task_id="kafka_data_stream",
python_callable=stream,
dag=dag,
)
spark_stream_task = DockerOperator(
task_id="pyspark_consumer",
image="rappel-conso/spark:latest",
api_version="auto",
auto_remove=True,
command="./bin/spark-submit --master local[*] --packages org.postgresql:postgresql:42.5.4,org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0 ./spark_streaming.py",
docker_url='tcp://docker-proxy:2375',
environment={'SPARK_LOCAL_HOSTNAME': 'localhost'},
network_mode="airflow-kafka",
dag=dag,
)
kafka_stream_task >> spark_stream_task
Вот ключевые элементы этой конфигурации:
- Задачи настроены на ежедневное выполнение.
- Первая задача ― потоковая задача Kafka Stream Task ― реализуется для запуска потоковой функции Kafka с помощью PythonOperator. Здесь выполняется потоковая передача данных из API RappelConso в тему Kafka, инициируется рабочий процесс обработки данных.
- Следующая ― потоковая задача Spark Stream Task, выполняемая с помощью DockerOperator. В ней запускается контейнер Docker с пользовательским образом Spark, который занимается обработкой полученных от Kafka данных.
- Задачи располагаются последовательно: задача обработки Spark предваряется потоковой Kafka. Такой порядок очень важен: сначала выполняется потоковая передача и загрузка данных в Kafka, затем их обработка со Spark.
DockerOperator
С помощью DockerOperator запускаются соответствующие задачам контейнеры Docker. Преимущества этого подхода ― проще управление пакетами, лучше изоляция, повышенная тестопригодность.
Продемонстрируем ключевые особенности этого оператора в потоковой задаче Spark:
- Воспользуемся образом
rappel-conso/spark:latest. - Внутри контейнера запускается команда отправки Spark, включаются необходимые пакеты для интеграции PostgreSQL и Kafka, указываются master в качестве локального и скрипт
spark_streaming.py, в котором содержится логика для задания Spark. - docker_url ― URL-адрес хоста, на котором запущен демон Docker. Естественное решение ― задать его как
unix://var/run/docker.sockи смонтироватьvar/run/docker.sockв airflow-контейнере Docker. Одна из проблем такого подхода ― ошибка разрешения использовать сокет-файл внутри airflow-контейнера. Изменение разрешений с помощьюchmod 777 var/run/docker.sockсопряжено со значительными рисками безопасности. Мы реализовали более безопасное решение:bobrik/socatв качестве docker-proxy. Этим прокси, определенным в службе Docker Compose, прослушивается TCP-порт 2375, и в сокет Docker перенаправляются запросы:
docker-proxy:
image: bobrik/socat
command: "TCP4-LISTEN:2375,fork,reuseaddr UNIX-CONNECT:/var/run/docker.sock"
ports:
- "2376:2375"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
- airflow-kafka
В DockerOperator доступ к хосту Docker /var/run/docker.sock получается через URL-адрес tcp://docker-proxy:2375, как описано здесь и тут.
- Наконец, устанавливаем для airflow-kafka сетевой режим: такая же сеть, как прокси, и запускаемый с помощью Docker Kafka. Это важно, поскольку данные из темы Kafka получаются заданием Spark, поэтому необходимо обеспечить взаимодействие обоих контейнеров.
Определив логику DAG, разберемся с конфигурацией служб Airflow в файле docker-compose-airflow.yaml.
Конфигурация Airflow
За основу файла Compose для Airflow взят официальный файл Apache Airflow docker-compose.
Согласно этой статье, предлагаемая версия Airflow очень ресурсоемка главным образом потому, что в core-executor задан CeleryExecutor, более адаптированный для распределенных и крупномасштабных задач обработки данных. Поскольку у нас небольшая рабочая нагрузка, одноузлового LocalExecutor достаточно.
Вот изменения, внесенные нами в конфигурацию Airflow docker-compose:
- Переменной окружения AIRFLOW__CORE__EXECUTOR задано значение LocalExecutor.
- Службы airflow-worker и flower удалены, так как они рабочие только для исполнителя Celery. Также удалена служба кэша redis: это бэкенд для Celery. Не нужен нам и airflow-triggerer, удаляем его.
- Базовый образ
${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.3}для остальных служб, в частности планировщика scheduler и веб-сервера webserver, заменен пользовательским образом, собираемым при запуске docker-compose:
version: '3.8'
x-airflow-common:
&airflow-common
build:
context: .
dockerfile: ./airflow_resources/Dockerfile
image: de-project/airflow:latest
- Смонтированы необходимые для Airflow тома. AIRFLOW_PROJ_DIR ― каталог проекта Airflow, который мы определим позже. Также, чтобы взаимодействовать с серверами начальной загрузки Kafka, установлена сеть airflow-kafka:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/config:/opt/airflow/config
- ./src:/opt/airflow/dags/src
- ./data/last_processed.json:/opt/airflow/data/last_processed.json
user: "${AIRFLOW_UID:-50000}:0"
networks:
- airflow-kafka
Теперь создадим переменные окружения для docker-compose:
echo -e "AIRFLOW_UID=$(id -u)\nAIRFLOW_PROJ_DIR=\"./airflow_resources\"" > .env
Здесь AIRFLOW_UID ― это идентификатор пользователя в контейнерах Airflow, а AIRFLOW_PROJ_DIR ― каталог проекта Airflow.
Теперь все настроено, запускаем службу Airflow:
docker compose -f docker-compose-airflow.yaml up
Затем, перейдя по URL-адресу http://localhost:8080, получаем доступ к пользовательскому интерфейсу Airflow:

По умолчанию имя пользователя и пароль одинаковы: airflow. Авторизовавшись, видим список всех Dag для Airflow. Нажимаем dag проекта kafka_spark_dag:
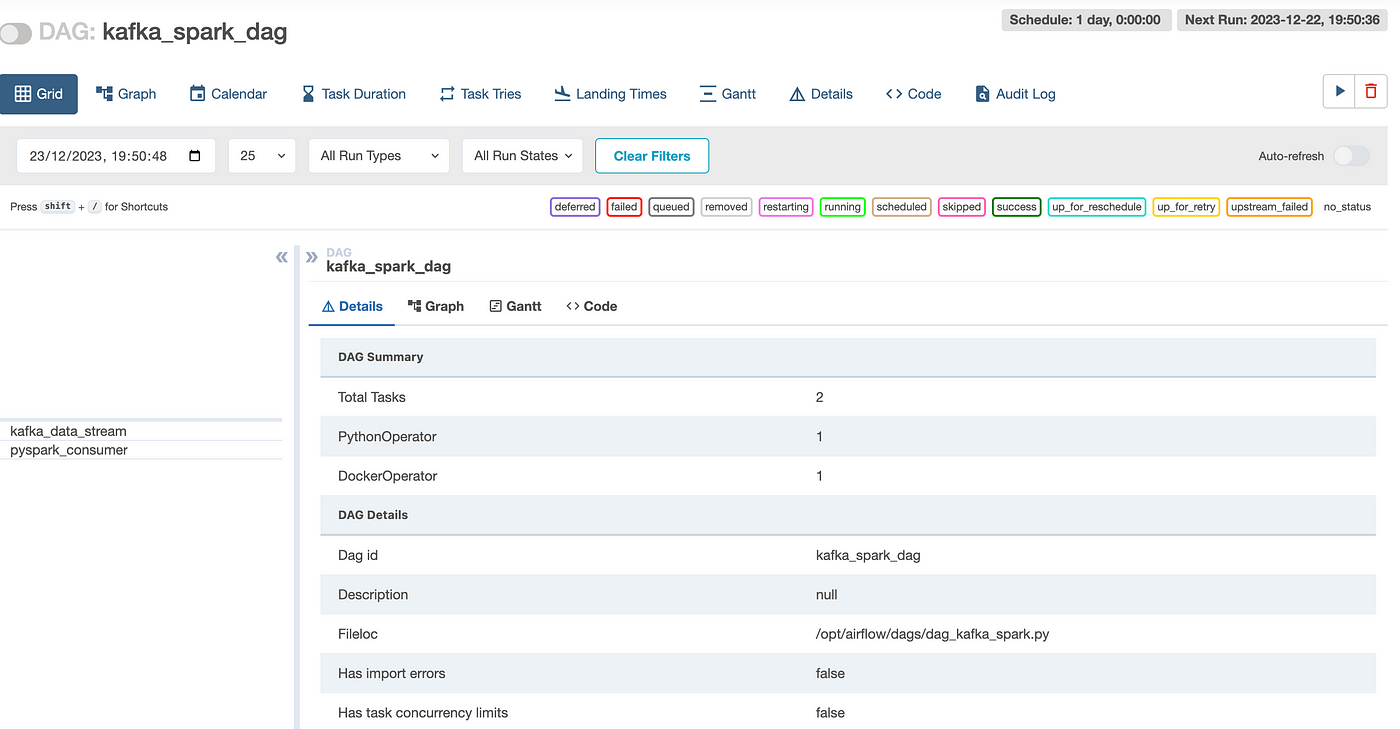
Запускаем задачу, нажимая кнопку рядом с DAG: kafka_spark_dag.
Теперь во вкладке Graph проверим статус задач. Если задача зеленая, она выполнена. Когда все завершено, получаем:

Следующим SQL-запросом в «Query Tool» pgAdmin проверяем, что rappel_conso_table заполнена данными:
SELECT count(*) FROM rappel_conso_table
Когда я делал этот запрос в январе 2024 года, вернулось в общей сложности 10 022 строки. Примерно такие же результаты должны быть и у вас.
Заключение
Мы поэтапно создали простой, но функциональный конвейер с Kafka, Airflow, Spark, PostgreSQL и Docker. Предназначенный в первую очередь для начинающих и тех, кто интересуется инженерией данных, он заключает в себе практический подход к пониманию и реализации ключевых концепций потоковой передачи, обработки и хранения данных.
В этом руководстве подробно рассмотрен каждый компонент конвейера: от настройки Kafka для потоковой передачи данных и использования Airflow для оркестрации задач до обработки данных с помощью Spark и их сохранения в PostgreSQL. Использование Docker на протяжении всего проекта упрощает настройку, обеспечивает согласованность в различных средах.
Важно отметить: хотя эта настройка идеальна для обучения и небольших проектов, ее масштабирование для применения в продакшене потребует учета дополнительных факторов, особенно безопасности и оптимизации производительности.
Дальнейшие усовершенствования связаны с интеграцией более продвинутых методов обработки данных, изучением аналитики в режиме реального времени или даже расширением конвейера и включением источников данных посложнее.
Фактически этот проект — отправная точка для желающих заняться инженерией данных, прочный фундамент для понимания азов и дальнейшего изучения этой сферы.
Во второй части научимся эффективно использовать данные, хранящиеся в PostgreSQL, рассмотрим агенты на основе больших языковых моделей и различные инструменты для взаимодействия с базой данных, применяя запросы на естественном языке. Так что не пропустите.