Создание приложения-чата с LangChain, большими языковыми моделями и Streamlit для взаимодействия со сложной базой данных SQL. Часть 2.
Продолжаем проект, в котором используются данные API RappelConso, французского общедоступного сервиса, где публикуется информация об отозванных из продажи во Франции продуктах.
Ранее, применяя различные инструменты, мы настроили конвейер, чтобы запрашивать данные из API и сохранять их в PostgreSQL.
Во второй и заключительной части, чтобы взаимодействовать со сложной базой данных при помощи агентов и инструментов Langchain, разработаем на основе яз
Создание приложения-чата с LangChain, большими языковыми моделями и Streamlit для взаимодействия со сложной базой данных SQL. Часть 2...
Продолжаем проект, в котором используются данные API RappelConso, французского общедоступного сервиса, где публикуется информация об отозванных из продажи во Франции продуктах.
Ранее, применяя различные инструменты, мы настроили конвейер, чтобы запрашивать данные из API и сохранять их в PostgreSQL.
Во второй и заключительной части, чтобы взаимодействовать со сложной базой данных при помощи агентов и инструментов Langchain, разработаем на основе языковой модели приложение-чат, а затем развернем его со Streamlit.
Содержание
- Обзор
- Настройка
- Агент SQL
- Инструментарий базы данных SQL
- Дополнительные инструменты
- Реализация функционала памяти
- Создание приложения со Streamlit
- Наблюдения и усовершенствования
- Заключение
- Использованные материалы
Обзор
Сделаем чат-бот, способный «понимать» естественный язык и создавать SQL-запросы, предоставим ему дополнительные инструменты для их выполнения и взаимодействия с базой данных RappelConso через фреймворк Langchain. Для запоминания прошлых взаимодействий с пользователями снабдим его функционалом памяти, а для удобства использования превратим с помощью Streamlit в веб-приложение с чатом:
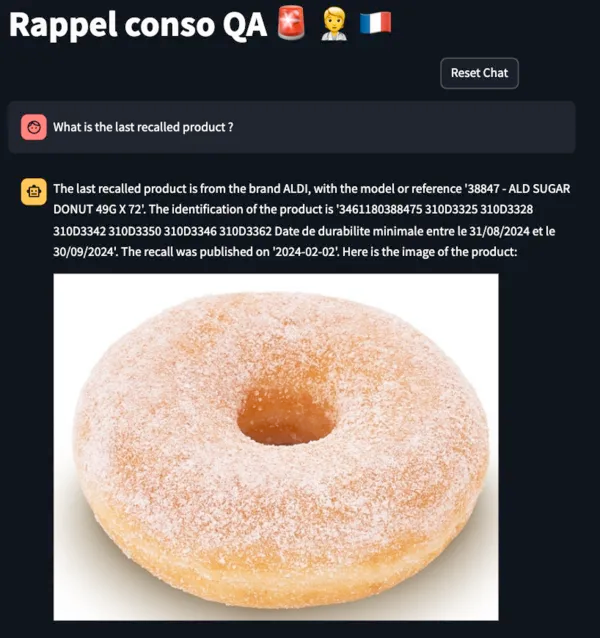
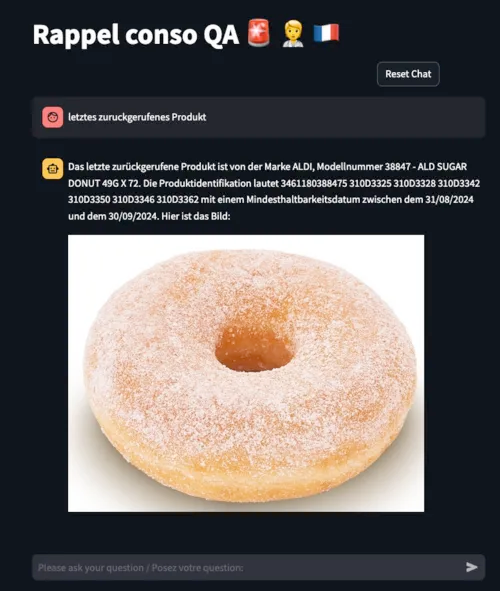
Вот демоверсия финального приложения:
Чат-бот отвечает на запросы различной сложности: от количества категорий отозванных товаров до конкретных вопросов о продуктах или брендах. Соответствующие запросу столбцы определяются с помощью имеющихся в его распоряжении инструментов. Чат-бот отвечает на языках, совместимых с ASCII: английском, французском, немецком и т. д.
Глоссарий
Пробежимся по ключевым терминам:
- Langchain ― это фреймворк с открытым исходным кодом для создания приложений с большими языковыми моделями.
- Агенты ― компоненты Langchain, которыми при помощи языковой модели решается, какие действия выполнять и в каком порядке. У агента обычно имеется доступ к набору функций Tools («Инструменты»). Какой инструмент применять, определяется на основе пользовательского ввода.
- Инструменты ― функции, вызываемые агентом для взаимодействия с внешним миром. Максимально полезны для агента те, которые хорошо описаны.
- Инструментарий ― набор связанных инструментов. Подробнее о применяемом в этом проекте SQLDatabaseToolkit ― ниже.
- Базы данных SQL ― основа с запрашиваемыми данными. В проекте используется Postgres.
- Streamlit ― фреймворк на Python, которым очень просто создавать интерактивные веб-приложения.
Переходим к техническим деталям.
Настройка
Сначала клонируем репозиторий Github:
git clone https://github.com/HamzaG737/rappel-conso-chat-app.git
Перейдя в корневой каталог, устанавливаем требования для пакетов:
pip install -r requirements.txt
В этом проекте мы экспериментировали с двумя большими языковыми моделями из OpenAI: gpt-3.5-turbo-1106 и gpt-4–1106-preview. Вторая лучше справляется со сложными запросами, поэтому она стала моделью по умолчанию.
Настройка базы данных
В первой части мы настроили конвейер для потоковой передачи данных из исходного API непосредственно в базу данных Postgres. Более простое решение ― скрипт, с помощью которого все данные передаются из API прямо в Postgres без настройки всего конвейера.
Сначала устанавливаем Docker. Затем задаем POSTGRES_PASSWORD в качестве переменной окружения. По умолчанию это будет строковое "postgres".
Запускаем сервер Postgres с помощью yaml-файла docker-compose в корневом каталоге проекта:
docker-compose -f docker-compose-postgres.yaml up -d
После этого скриптом database/stream_data.py создается таблица rappel_conso_table, выполняются потоковая передача данных из API в базу данных и быстрая их проверка посредством подсчета строк. В феврале 2024 года было около 10 400 строк, ожидайте примерно столько же.
Запускаем скрипт:
python database/stream_data.py
Передача данных продолжается минуту или чуть больше в зависимости от скорости интернет-соединения.
В rappel_conso_table всего 25 столбцов, большинство из них текстового типа и принимают бесконечные значения. Вот самые важные столбцы:
- reference_fiche (справочный перечень): уникальный идентификатор отозванного продукта, это первичный ключ Postgres;
- categorie_de_produit (категория товара): еда, электроприборы, инструменты, транспортные средства и т. д.;
- sous_categorie_de_produit (подкатегория товара): для категории еды, например это мясо, молочные продукты, крупы;
- motif_de_rappel (причина изъятия): одно из важнейших полей;
- date_de_publication: дата опубликования;
- risques_pour_le_consommateur: риски потребителя при использовании продукта;
- имеются еще поля с различными ссылками на изображение продукта, список поставщиков и т. д.
Полный список столбцов ― в файле constants.py под константой RAPPEL_CONSO_COLUMNS.
Агенту важно четко различать все эти столбцы, особенно в случаях неоднозначных пользовательских запросов. Для точного генерирования SQL-запросов ему необходим контекст, предоставляемый SQLDatabaseToolkit и дополнительными инструментами.
Агент SQL
В LangChain имеется гибкий способ взаимодействия с базами данных SQL ― агент SQL.
Вот его преимущества:
- отвечает на запросы не только о структуре БД, например сведениях по конкретной таблице, но и содержимом этих баз данных;
- эффективно обрабатывает ошибки: агентом SQL выявляется и исправляется проблема, из-за которой при выполнении запроса возникла ошибка, а после выполняется скорректированный запрос.
В Langchain агент SQL инициализируется функцией create_sql_agent:
from langchain.agents import create_sql_agent
agent = create_sql_agent(
llm=llm_agent,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
toolkit=toolkit,
verbose=True,
)
- Здесь llm ― основа большой языковой модели агента. Для этой задачи выбраны GPT-модели OpenAI, сгодятся и другие. Большая языковая модель для агента определяется так:
from langchain.chat_models import ChatOpenAI
from constants import chat_openai_model_kwargs, langchain_chat_kwargs
# Дополнительно: задаем API-ключ для OpenAI, если он не задан в среде.
# os.environ["OPENAI_API_KEY"] = "xxxxxx"
def get_chat_openai(model_name):
llm = ChatOpenAI(
model_name=model_name,
model_kwargs=chat_openai_model_kwargs,
**langchain_chat_kwargs
)
return llm
- Сейчас в
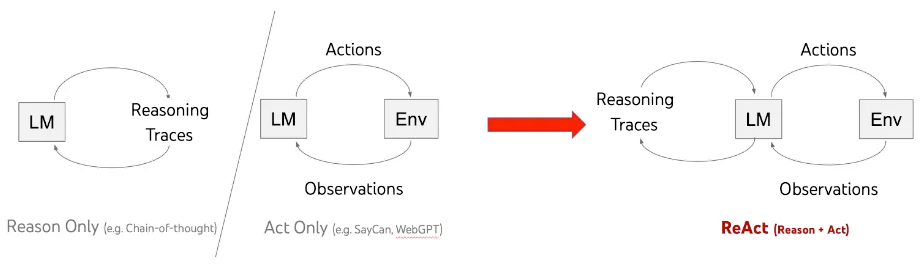
create_sql_agentподдерживается два типа агентов: функции OpenAI и агенты ReAct. Выбраны последние: они проще интегрируются с функционалом памяти. Моделью агента ReAct с помощью больших языковых моделей генерируются вместе рассуждения и специфичные для задач действия. Так действия агента при работе с исключениями планируются, отслеживаются, корректируются, а агент подключается к внешним источникам, таким как базы знаний, для получения дополнительной информации, отчего повышается его эффективность в задачах. Подробнее об этом фреймворке ― здесь.
- Наконец,
toolkitв функцииcreate_sql_agent― набор инструментов SQL для взаимодействия с базой данных. Подробнее об этом ― далее.
Инструментарий базы данных SQL
В SQLDatabaseToolkit содержатся инструменты, которыми:
- Создаются и выполняются запросы. В этом примере агентом ReAct вызывается инструмент
sql_db_queryс SQL-запросом во входных данных, а после анализируются результаты базы данных и формулируется ответ для пользователя:
Action: sql_db_query
Action Input: SELECT reference_fiche, nom_de_la_marque_du_produit, noms_des_modeles_ou_references, date_de_publication, liens_vers_les_images FROM rappel_conso_table WHERE categorie_de_produit = 'Alimentation' ORDER BY date_de_publication DESC LIMIT 1
Observation: [('2024-01-0125', 'MAITRE COQ', 'Petite Dinde', '2024-01-13', 'https://rappel.conso.gouv.fr/image/ea3257df-7a68-4b49-916b-d6f019672ed2.jpg https://rappel.conso.gouv.fr/image/2a73be1e-b2ae-4a31-ad38-266028c6b219.jpg https://rappel.conso.gouv.fr/image/95bc9aa0-cc75-4246-bf6f-b8e8e35e2a88.jpg')]
Thought:I now know the final answer to the question about the last recalled food item.
Final Answer: The last recalled food item is "Petite Dinde" by the brand "MAITRE COQ", which was published on January 13, 2024. You can find the images of the recalled food item here: [lien vers l'image](https://rappel.conso.gouv.fr/image/ea3257df-7a68-4b49-916b-d6f019672ed2.jpg), [lien vers l'image](https://rappel.conso.gouv.fr/image/2a73be1e-b2ae-4a31-ad38-266028c6b219.jpg), [lien vers l'image](https://rappel.conso.gouv.fr/image/95bc9aa0-cc75-4246-bf6f-b8e8e35e2a88.jpg).
- С помощью
sql_db_query_checkerпроверяется синтаксис запроса:
Action: sql_db_query_checker
Action Input: SELECT reference_fiche, nom_de_la_marque_du_produit, noms_des_modeles_ou_references, date_de_publication, liens_vers_les_images FROM rappel_conso_table WHERE categorie_de_produit = 'Alimentation' ORDER BY date_de_publication DESC LIMIT 1
Observation: ```sql
SELECT reference_fiche, nom_de_la_marque_du_produit, noms_des_modeles_ou_references, date_de_publication, liens_vers_les_images FROM rappel_conso_table WHERE categorie_de_produit = 'Alimentation' ORDER BY date_de_publication DESC LIMIT 1
```
Thought:The query has been checked and is correct. I will now execute the query to find the last recalled food item.
- С помощью
sql_db_schemaизвлекаются описания таблицы:
Action: sql_db_schema
Action Input: rappel_conso_table
Observation:
CREATE TABLE rappel_conso_table (
reference_fiche TEXT NOT NULL,
liens_vers_les_images TEXT,
lien_vers_la_liste_des_produits TEXT,
lien_vers_la_liste_des_distributeurs TEXT,
lien_vers_affichette_pdf TEXT,
lien_vers_la_fiche_rappel TEXT,
date_de_publication TEXT,
date_de_fin_de_la_procedure_de_rappel TEXT,
categorie_de_produit TEXT,
sous_categorie_de_produit TEXT,
nom_de_la_marque_du_produit TEXT,
noms_des_modeles_ou_references TEXT,
identification_des_produits TEXT,
conditionnements TEXT,
temperature_de_conservation TEXT,
zone_geographique_de_vente TEXT,
distributeurs TEXT,
motif_du_rappel TEXT,
numero_de_contact TEXT,
modalites_de_compensation TEXT,
risques_pour_le_consommateur TEXT,
recommandations_sante TEXT,
date_debut_commercialisation TEXT,
date_fin_commercialisation TEXT,
informations_complementaires TEXT,
CONSTRAINT rappel_conso_table_pkey PRIMARY KEY (reference_fiche)
)
/*
Одна строка из таблицы «rappel_conso_table»:
reference_fiche liens_vers_les_images lien_vers_la_liste_des_produits lien_vers_la_liste_des_distributeurs lien_vers_affichette_pdf lien_vers_la_fiche_rappel date_de_publication date_de_fin_de_la_procedure_de_rappel categorie_de_produit sous_categorie_de_produit nom_de_la_marque_du_produit noms_des_modeles_ou_references identification_des_produits conditionnements temperature_de_conservation zone_geographique_de_vente distributeurs motif_du_rappel numero_de_contact modalites_de_compensation risques_pour_le_consommateur recommandations_sante date_debut_commercialisation date_fin_commercialisation informations_complementaires
2021-04-0165 https://rappel.conso.gouv.fr/image/bd8027eb-ba27-499f-ba07-9a5610ad8856.jpg None None https://rappel.conso.gouv.fr/affichettePDF/225/Internehttps://rappel.conso.gouv.fr/fiche-rappel/225/Interne 2021-04-22 mercredi 5 mai 2021 Alimentation Cereales et produits de boulangerie GERBLE BIO BISCUITS 3 GRAINES BIO 3175681257535 11908141 Date de durabilite minimale 31/03/2022 ETUI CARTON 132 g Produit a conserver a temperature ambiante France entiere CASINO Presence possible d'oxyde d'ethylene superieure a la limite autorisee sur un lot de matiere premiere 0805293032 Remboursement Produits phytosanitaires non autorises Ne plus consommer Rapporter le produit au point de vente 19/03/2021 02/04/2021 None
Прежде чем определять класс SQLDatabaseToolkit, инициализируем обертку SQLDatabase вокруг базы данных Postgres:
import os
from langchain.sql_database import SQLDatabase
from .constants_db import port, password, user, host, dbname
url = f"postgresql+psycopg2://{user}:{password}@{host}:{port}/{dbname}"
TABLE_NAME = "rappel_conso_table"
db = SQLDatabase.from_uri(
url,
include_tables=[TABLE_NAME],
sample_rows_in_table_info=1,
)
Параметром sample_rows_in_table_info определяется количество строк-примеров, добавляемых к каждому описанию таблицы. С добавлением таких строк повышается производительность агента, как показано в этой работе. И, когда он обращается к описанию таблицы за более четким пониманием, получает из нее образец строки и схему таблицы.
Определим инструментарий SQL:
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
def get_sql_toolkit(tool_llm_name):
llm_tool = get_chat_openai(model_name=tool_llm_name)
toolkit = SQLDatabaseToolkit(db=db, llm=llm_tool)
return toolkit
Дополнительные инструменты
Учитывая сложность таблицы, для полного понимания информации, содержащейся в базе данных, одной схемы и образца строки агенту недостаточно. Например, необходимо распознавать, что запросом об автомобилях подразумевается поиск в столбце Category («Категория») значения Automobiles et moyens de déplacement («Автомобили и транспортные средства»). Поэтому для большего контекста о базе данных агенту нужны дополнительные инструменты.
Вот они:
get_categories_and_sub_categories: из столбцовcategoryиsub_categoryагенту предоставляется список отдельных элементов. Такой подход эффективен из-за относительно небольшого количества уникальных значений в этих столбцах. Будь там их сотни или тысячи, использовался бы инструмент поиска. В таких случаях, когда пользователь спрашивает о категории, агентом разыскиваются наиболее похожие в векторной базе данных, где хранятся вложения различных значений. Эти категории затем применяются агентом в SQL-запросах. Так как уникальных значений в столбцахcategoryиsub_categoryнемного, просто возвращаем непосредственно список:
from langchain.tools import tool, Tool
import ast
import json
from sql_agent.sql_db import db
def run_query_save_results(db, query):
res = db.run(query)
res = [el for sub in ast.literal_eval(res) for el in sub]
return res
def get_categories(query: str) -> str:
"""
Так же можно получить «categories» и «sub_categories». Возвращается json, где ключ ― «categories» или «sub_categories»,
а значение ― список уникальных элементов для того или другого или обоих.
"""
sub_cat = run_query_save_results(
db, "SELECT DISTINCT sous_categorie_de_produit FROM rappel_conso_table"
)
cat = run_query_save_results(
db, "SELECT DISTINCT categorie_de_produit FROM rappel_conso_table"
)
category_str = (
"List of unique values of the categorie_de_produit column : \n"
+ json.dumps(cat, ensure_ascii=False)
)
sub_category_str = (
"\n List of unique values of the sous_categorie_de_produit column : \n"
+ json.dumps(sub_cat, ensure_ascii=False)
)
return category_str + sub_category_str
get_columns_descriptions: поскольку напрямую передавать описания столбцов в схему нельзя, сделали дополнительный инструмент, которым для каждого неоднозначного столбца возвращается краткое описание. Вот примеры:
"reference_fiche": "primary key of the database and unique identifier in the database. ",
"nom_de_la_marque_du_produit": "A string representing the Name of the product brand. Example: Apple, Carrefour, etc ... When you filter by this column,you must use LOWER() function to make the comparison case insensitive and you must use LIKE operator to make the comparison fuzzy.",
"noms_des_modeles_ou_references": "Names of the models or references. Can be used to get specific infos about the product. Example: iPhone 12, etc, candy X, product Y, bread, butter ...",
"identification_des_produits": "Identification of the products, for example the sales lot.",
def get_columns_descriptions(query: str) -> str:
"""
Так же можно получить описание столбцов в таблице «rappel_conso_table».
"""
return json.dumps(COLUMNS_DESCRIPTIONS)
get_today_date: инструмент, которым с помощью библиотеки Python datetime извлекается сегодняшняя дата, применяется агентом в отношении временны́х аспектов. Например: «Какие продукты отозваны с прошлой недели?»
from datetime import datetime
def get_today_date(query: str) -> str:
"""
Так же можно получить сегодняшнюю дату.
"""
# Получение сегодняшней даты в строковом формате
today_date_string = datetime.now().strftime("%Y-%m-%d")
return today_date_string
Создаем список всех этих инструментов и передаем в функцию create_sql_agent. Для каждого инструмента в наборе предоставляемых агенту инструментов определяем уникальное название. Описание необязательно, но очень рекомендуется как дополнительная информация:
def sql_agent_tools():
tools = [
Tool.from_function(
func=get_categories,
name="get_categories_and_sub_categories",
description="""
Так же можно получить «categories» и «sub_categories». Возвращается json, где ключ ― «categories» или «sub_categories»,
а значение ― список уникальных элементов для того или другого или обоих.
""",
),
Tool.from_function(
func=get_columns_descriptions,
name="get_columns_descriptions",
description="""
Так же можно получить описание столбцов в таблице «rappel_conso_table».
""",
),
Tool.from_function(
func=get_today_date,
name="get_today_date",
description="""
Так же можно получить сегодняшнюю дату.
""",
),
]
return tools
extra_tools = sql_agent_tools()
agent = create_sql_agent(
llm=llm_agent,
toolkit=toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
extra_tools=extra_tools,
verbose=True,
)
Иногда агенту недостаточно описаний инструментов, чтобы «понять», когда их использовать. Тогда меняем агенту концовку подсказки большой языковой модели, то есть суффикс. Подсказка состоит из трех частей:
- Префикс. Это строка перед списком инструментов. Мы работаем со стандартным префиксом, в котором агенту указывается, как создавать и выполнять SQL-запросы в ответ на вопросы пользователей, ограничивать количество результатов до 10, тщательно проверять запросы и не вносить изменений в базу данных.
- Список инструментов. В этой части перечислены все инструменты в распоряжении агента.
- Суффикс. А здесь агенту указывается, как обрабатывать и «обдумывать» вопрос пользователя.
Вот стандартный суффикс для агента SQL ReAct в Langchain:
SQL_SUFFIX = """Начинаем!
Вопрос: {input}
Мысль: что запрашивать, смотрим в таблице базе данных. Затем запрашиваем схему наиболее релевантных таблиц.
{agent_scratchpad}"""
input и agent_scratchpad — это два заполнителя. input — запрос пользователя, а agent_scratchpad — история вызовов инструмента и соответствующие выходные данные инструмента.
Удлиним часть «Мысль» и добавим указания, какие инструменты использовать и когда:
CUSTOM_SUFFIX = """Начинаем!
Вопрос: {input}
Мыслительный процесс: очень важно не выдумывать информацию, которой в базе данных нет, и не галлюцинировать;
необходимо поддержание достоверности. Если пользователь указывает категорию, пытаемся соотнести ее с категориями в столбцах «categories_produits»
или «sous_categorie_de_produit» таблицы «rappel_conso_table», используя инструмент «get_categories» с пустой строкой в качестве аргумента.
Затем с помощью инструмента «sql_db_schema» получаем схему таблицы «rappel_conso_table».
Для продвинутого понимания столбцов «rappel_conso_table», за исключением простых задач, очень рекомендуется инструмент «get_columns_descriptions».
Когда указывается марка продукта, ищем в столбце «nom_de_la_marque_du_produit», когда тип — в столбце «noms_des_modeles_ou_references».
Инструментом «get_today_date», которому в качестве аргумента требуется пустая строка, предоставляется сегодняшняя дата.
В SQL-запросах со строковыми или текстовыми сравнениями без учета регистра применяется функция «LOWER()», для нечеткого сопоставления — оператор «LIKE».
На запросы для отозванных в данный момент продуктов возвращаются строки, в которых «date_de_fin_de_la_procedure_de_rappel» (дата окончания отзыва) — «null» или позже сегодняшней даты.
При представлении продуктов включаются ссылки на изображения из столбца «liens_vers_les_images» строго в формате: [lien vers l'image] url1, [lien vers l'image] url2 ... Предваряемые упоминанием на языке запроса: "here is(are) the image(s) :" («Вот изображение(-я):».
Кроме того, конкретная отозванная партия товара включается из столбца «identification_des_produits».
Финальный ответ предоставляется на языке пользовательского запроса.
{agent_scratchpad}
"""
Таким образом, агенту не только «известно» о его инструментах, но и даются оптимизированные рекомендации о том, когда их использовать.
Подкорректируем аргументы create_sql_agent с учетом нового суффикса:
agent = create_sql_agent(
llm=llm_agent,
toolkit=toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
suffix=CUSTOM_SUFFIX,
extra_tools=agent_tools,
verbose=True,
)
Другим вариантом было включение указаний в префикс. Однако, согласно эмпирическим наблюдениям, оно практически не сказалось на финальном ответе. Поэтому указания сохранили в суффиксе. Для детального сравнения двух подходов нужна всеобъемлющая оценка выходных данных модели.
Реализация функционала памяти
Неплохо было бы агенту «запоминать» прошлые взаимодействия и не начинать каждый диалог заново, особенно когда запросы связаны.
Этот функционал добавляется в несколько этапов:
- Сначала импортируем класс
ConversationBufferMemory, это буфер, в котором отслеживается история диалогов:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="history", input_key="input")
- Затем включаем в суффикс историю диалогов:
custom_suffix = """Начинаем!
Соответствующие части предыдущего диалога:
{history}
(Примечание: включаем эту информацию, только если она релевантна текущему запросу.)
Вопрос: {input}
Мыслительный процесс: очень важно не выдумывать информацию... (то же, что в предыдущем суффиксе)
{agent_scratchpad}
"""
- Наконец, корректируем функцию
create_sql_agent, добавляя историю в заполнители подсказки и включая память в аргументы исполнителя агента:
agent = create_sql_agent(
llm=llm_agent,
toolkit=toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
input_variables=["input", "agent_scratchpad", "history"],
suffix=custom_suffix,
agent_executor_kwargs={"memory": memory},
extra_tools=agent_tools,
verbose=True,
)
Так с помощью памяти агентом совершенствуется обработка связанных запросов в диалоге.
Создание приложения со Streamlit
Сделаем диалоговое приложение с большими языковыми моделями фреймворка Streamlit и следующими элементами чата:
st.chat_input: виджет ввода чата, через который пользователь вводит сообщение:

st.chat_message: этой функцией в приложение добавляется сообщение чата с отображением ввода от пользователя или от приложения, в первом аргументе указывается автор сообщения с параметрами «пользователь» или «ассистент» для применения соответствующих стилей и аватаров:

Для ведения истории диалогов воспользуемся состоянием сеанса Streamlit, благодаря сохранению контекста чата этой важной функцией обеспечивается хорошее пользовательское взаимодействие.
Подробнее о процессе создания диалогового приложения — здесь.
Поскольку агентом всегда возвращаются URL-адреса изображений, мы сделали функцию постобработки для их извлечения из этих адресов, форматирования выходных данных и отображения содержимого с помощью разметки и компонентов изображений Streamlit. Подробности реализации этой функциональности — в модуле streamlit_app/gen_final_output.py.
Запускаем приложение-чат:
streamlit run streamlit_app/app.py
Дальнейшие усовершенствования связаны с включением параметров выбора пользователями желаемой модели и конфигурирования API-ключа OpenAI, дополнительной настройки работы чата.
Наблюдения и усовершенствования
Вот выводы, полученные после запуска диалогов с агентом:
- GPT-4 значительно превосходит GPT-3.5, что неудивительно. Последняя хорошо справляется с простыми запросами, но обычно плохо с применением необходимых инструментов для дополнительного контекста о базе данных, что чревато частыми галлюцинациями.
- Чем сложнее вопрос пользователя, тем затратнее и медленнее GPT-4. При генерировании подробной информации, такой как схема базы данных, количество строк и описания столбцов, используется много токенов. Кроме того, если нужны подробные результаты, например информация о последних 10 отозванных продуктах, агентом обрабатываются выходные данные запроса вместе с действиями и наблюдениями инструментов, что очень дорого. Поэтому, чтобы избежать непредвиденных затрат, важно следить за использованием агента.
Чтобы повысить его производительность:
- совершенствуются подсказки, корректируются суффиксы и/или префиксы, при необходимости предвидятся и эффективно применяются нужные инструменты;
- в подсказку включаются примеры или задействуются инструменты поиска, и так находятся наиболее релевантные примеры для типичных пользовательских запросов, избавляя от необходимости повторно применять одни и те же инструменты для каждого нового вопроса;
- для определения, например, производительности больших языковых моделей, исходя из финального ответа, или для сравнения подсказок добавляется фреймворк оценки.
Заключение
Мы сделали приложение-чат на основе больших языковых моделей для взаимодействия с базами данных SQL через фреймворк Langchain для ответа на самые разные запросы пользователей задействовали фреймворк агента ReACT с различными инструментами SQL и дополнительными ресурсами, реализовали и развернули с помощью Streamlit функционал памяти, создали удобный интерфейс, в котором сложные запросы к базе данных упрощаются в диалоговом режиме.
Учитывая сложность базы данных и большое количество столбцов в ней, для этого решения потребовались полноценный набор инструментов и мощная большая языковая модель.
Мы уже говорили о том, как увеличить возможности чат-бота. Кроме того, большая языковая модель с точной настройкой в SQL-запросах — неплохая альтернатива общей модели вроде GPT. Благодаря ей заметно совершенствуется взаимодействие системы с базами данных, еще лучше разбирается она со сложными запросами и их обработкой.
Использованные материалы
- [2210.03629] ReAct: Синергия рассуждений и действий в языковых моделях (arxiv.org).
- База данных SQL Langchain.
- Агент SQL Langchain.
- Документация по агентам и инструментам Langchain.
- Создайте диалоговое приложение с большими языковыми моделями на Streamlit.
- Статья о больших языковых моделях и SQL в блоге Langchain.