Как создать платформу обработки и анализа данных за неделю.
Это, конечно, самый продолжительный мой проект (и самый дорогой). Тем не менее он замечателен, поэтому не могу не поделиться им с вами.
Постараюсь упростить свой рассказ, чтобы даже люди, не связанные с технологиями, смогли во всем разобраться. Почему?
У всего есть причина, и у этого проекта тоже.
Недавно я приобрел навыки системной инженерии, и решил применить их в сквозном проекте. Конечно, этот проект не самый лучший, но он помогает мн
Как создать платформу обработки и анализа данных за неделю...
Это, конечно, самый продолжительный мой проект (и самый дорогой). Тем не менее он замечателен, поэтому не могу не поделиться им с вами.
Постараюсь упростить свой рассказ, чтобы даже люди, не связанные с технологиями, смогли во всем разобраться.
Почему?
У всего есть причина, и у этого проекта тоже.
Недавно я приобрел навыки системной инженерии, и решил применить их в сквозном проекте. Конечно, этот проект не самый лучший, но он помогает мне быстро выполнять итерации и избегать ошибок (а также отвечает реальности современной инженерии данных, повсюду заявляющей о себе впечатляющими иконками инструментов).
Конечная цель
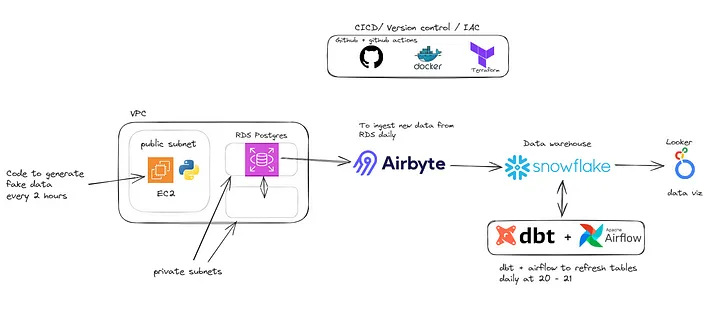
Конечной целью данного проекта является создание полнофункциональной платформы/конвейера обработки и анализа данных, которая будет ежедневно обновлять аналитические таблицы/дэшборды.
Инфраструктура
Как видно на изображении, для запуска проекта нужно было принять несколько решений:
- Откуда брать данные? RDS PostgreSQL + Python-скрипт в экземпляре EC2 для генерации новых данных каждые 2 часа.
- Где будут храниться данные для аналитики? Snowflake.
- Как связать эти два компонента? Airbyte (Cloud).
- Как сделать данные пригодными для аналитики/дэшбординга? DBT + Airflow.
Рассмотрим каждое решение отдельно.
Откуда брать данные?
Я очень устал от плоских файлов, поэтому подумал, что было бы неплохо создать скрипт, который бы генерировал фиктивные данные по расписанию (каждые 2 часа) и хранил бы их в базе данных Postgres (RDS).
Не буду углубляться в эту часть, поскольку она не является нашей основной целью.
Итак, вот краткий обзор модели данных исходной системы:
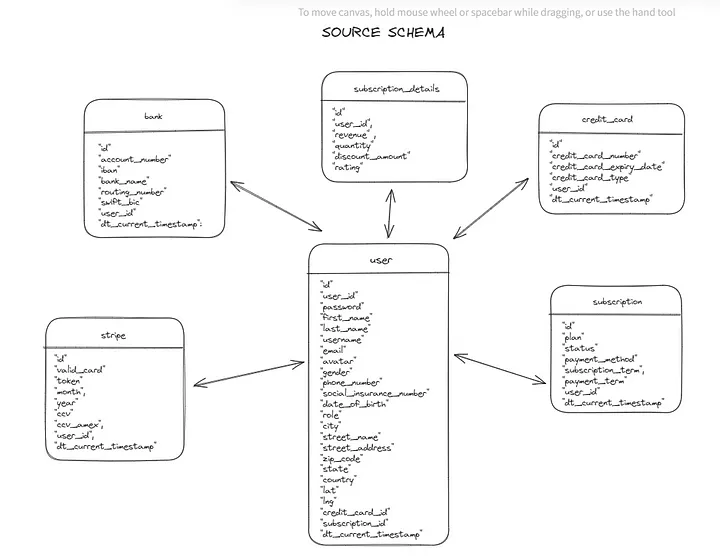
Эта модель данных намеренно базовая и “грязная”. Я хотел получить что-то “сырое”, чтобы было над чем поработать на этапе трансформации.
Когда у нас были готовы модель данных и Python-скрипт, мы перешли к созданию реляционной базы данных PostgreSQL, в которой хранились бы необработанные таблицы.
Воспользовавшись Terraform, мы создали:
- VPC (virtual private cloud — виртуальное приватное облако);
- две приватные подсети для размещения RDS (сервиса реляционной базы данных), а также группу безопасности для разрешения трафика на порт 5432;
- один экземпляр EC2 в публичной подсети для выполнения Python-скрипта (который также будет служить SSH-туннелем для подключения к базе данных с помощью Airbyte, поскольку база данных не является общедоступной по соображениям безопасности) и группу безопасности для разрешения SSH.
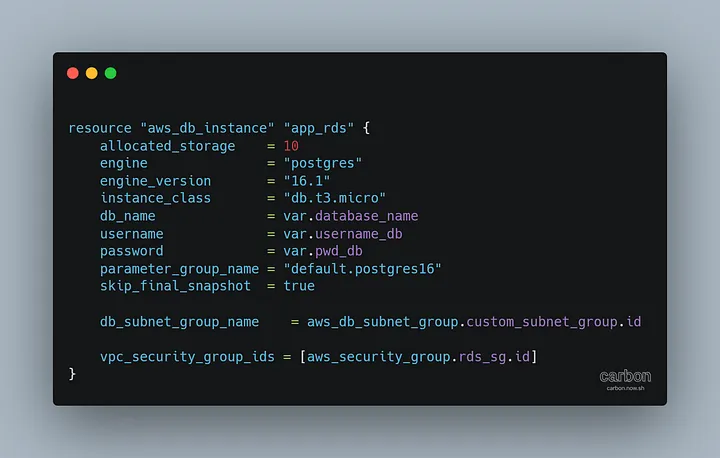
Вот как выглядит RDS в конечном итоге:
А вот как выглядит EC2, где будет размещен Python-скрипт:
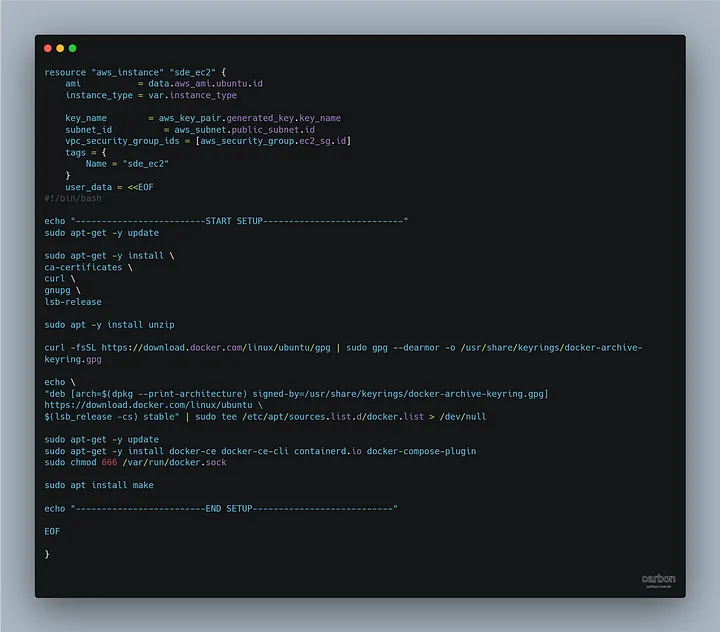
Вам, наверное, интересно, что делает этот длинный код.
Он просто создает экземпляр EC2, указывая AMI, группу безопасности, подсеть и user_data для установки Docker.
Итак, у нас есть ресурсы, созданные на облачной платформе AWS. Как теперь развернуть код на этом экземпляре EC2?
Используем конвейер CI/CD с действиями на GitHub:
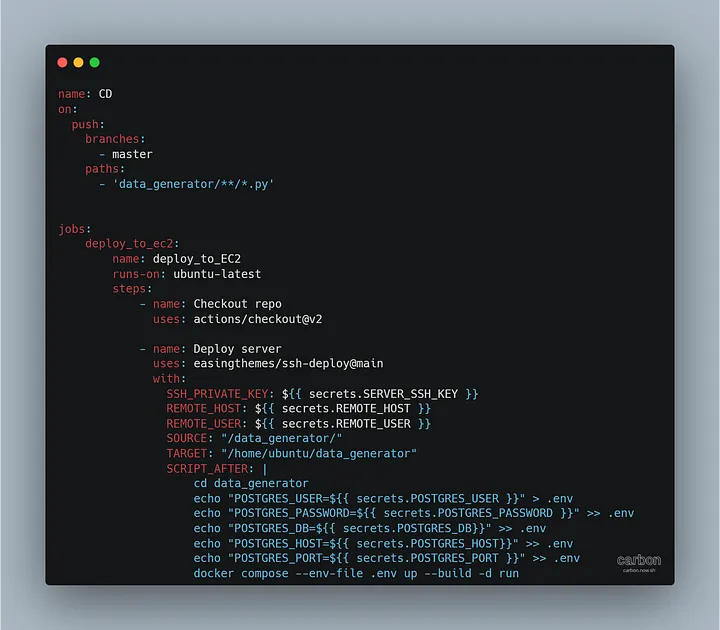
Что делает этот код?
- Позволяет подключиться к экземпляру EC2 с помощью SSH.
- Копирует контент каталога, содержащего скрипт Python, на этот EC2.
- Запускает контейнер.
Где будут храниться данные для аналитики?
Сейчас у нас есть данные, которые обновляются каждые два часа на RDS. Что по целевой системе? Ответ однозначен: Snowflake.
В этом разделе не так много интересного. Вот несколько слов о том, как я структурирую базу данных.
- RAW: база данных для хранения “сырых” данных, поступающих из Airbyte (схема: postgres_airbyte).
- ANALYTICS: производственная база данных (схемы: staging, intermediate, marts(finance)).
- DBT_DEV: база данных разработки (имеет те же схемы, что и производственная база данных).
- DATA_ENGINEER: роль для использования базы данных RAW и владения базами данных ANALYTICS и DBT_DEV.
- AIRBYTE_ROLE: используется Airbyte для записи в базу данных RAW (схема postgres_airbyte).
Как связать две системы? Как поглощать данные?
Изначально я предполагал написать для этой задачи собственный Python-скрипт на AWS Lambda. Однако его реализация заняла бы значительное количество времени, особенно учитывая необходимость включения функции CDC (Change Data Capture — отслеживание измененных данных) для захвата только новых данных из исходной системы.
Поэтому решил воспользоваться no-code/современными инструментами, составляющими основу современного стека данных (MDS).
Я выбрал Airbyte, точнее Airbyte Cloud. Хотя можно было выбрать версию с открытым исходным кодом и установить ее с помощью Docker на экземпляр EC2, я предпочел облачную версию, предлагающую 14-дневную бесплатный пробный период.
Синхронизация данных из исходной системы в целевую с помощью Airbyte очень проста. Тут практически нечего объяснять.
Что касается режима синхронизации, я выбрал “Incremental” (“Инкрементный”), при котором Airbyte извлекает только новые данные из исходной системы, и “Append + Deduped” (“Добавление данных + Удаление повторов”), который не требует пояснений: Airbyte обеспечивает уникальность каждой строки на основе указанного столбца (обычно это первичный ключ).
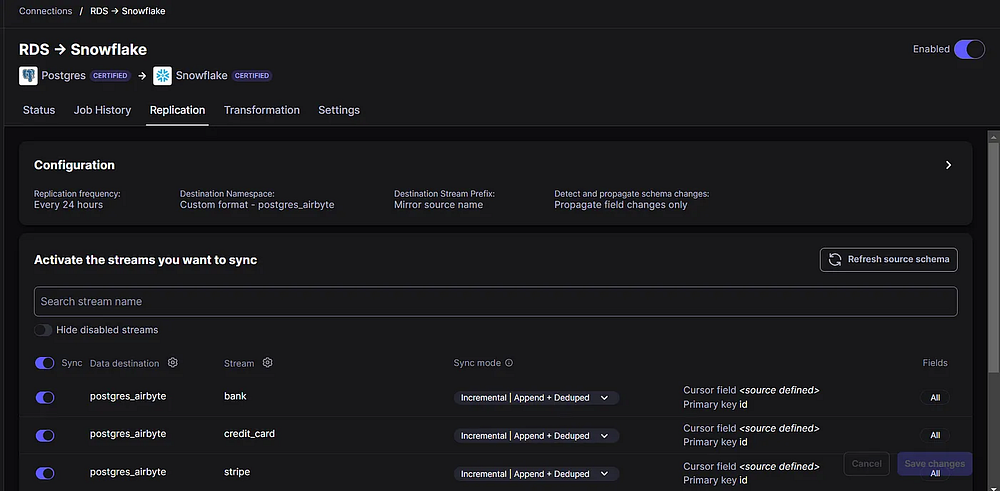
Благодаря современному стеку данных, мы настроили и запустили конвейер поглощения данных менее чем за 10 минут!
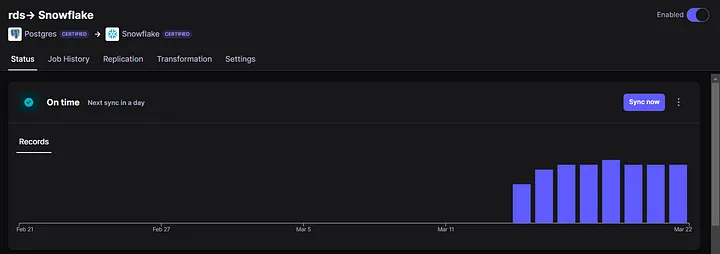
P. S. Airbyte синхронизирует данные каждый день в 5 часов вечера (запомните это, пригодится позже).
Как сделать данные пригодными для аналитики/дэшбординга?
Как можно судить по модели данных исходной системы, мы не могли использовать эти таблицы для аналитики и дэшбординга. Вот тут-то и пригодился подход Кимбалла — методология проектирования и управления хранилищами данных, разработанная Ральфом Кимбаллом.
Взгляните на эту красивую и простую схему:
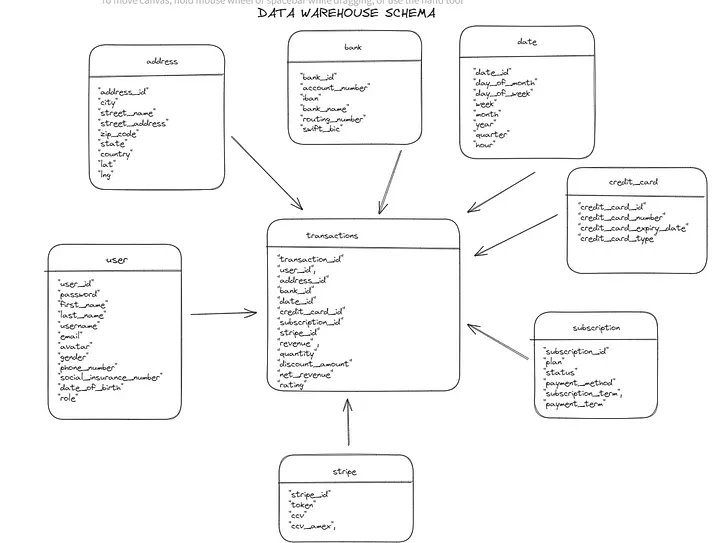
P. S. Наша конечная цель — анализ метрик плана подписки.
Теперь у нас есть желаемая модель данных, но как создать таблицы?
Именно здесь на помощь приходит DBT (data build tool — инструмент преобразования данных).
Вот как мы структурировали DBT-проект.
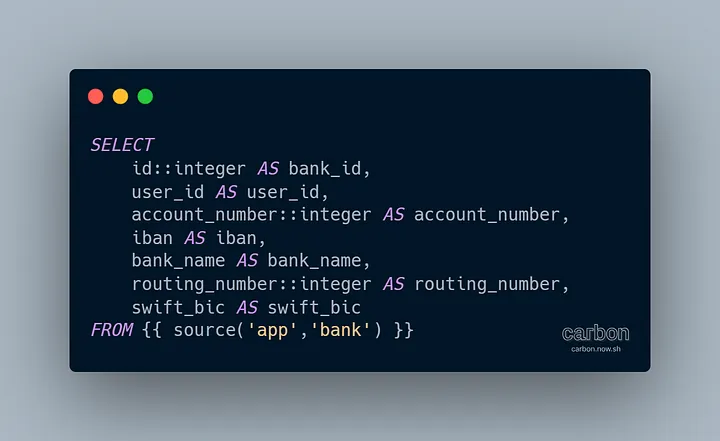
models/staging: это модели, которые хранятся в схеме staging и подвергаются простому приведению типов и быстрым преобразованиям.
Пример созданной нами модели (stg_bank):
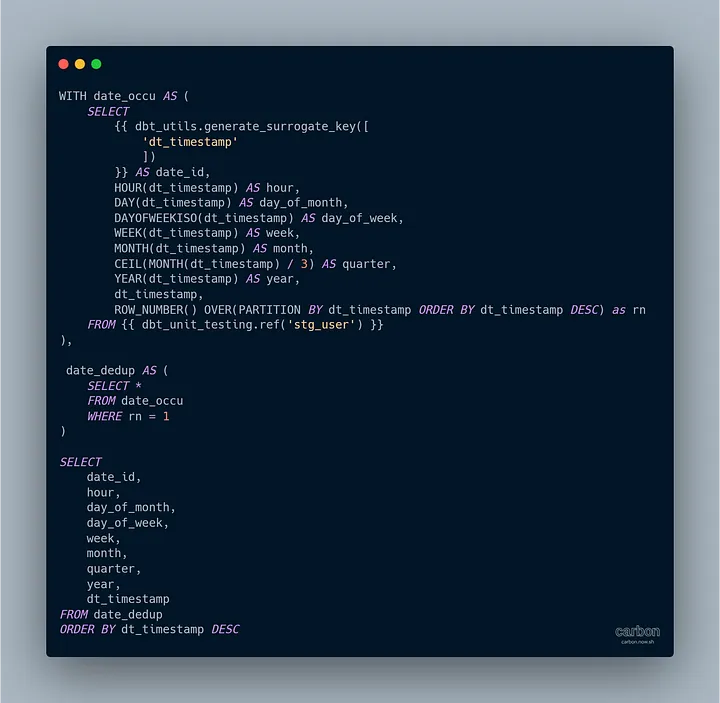
models/intermediate: здесь мы создаем таблицы фактов и измерений.
Вот пример (int_date):
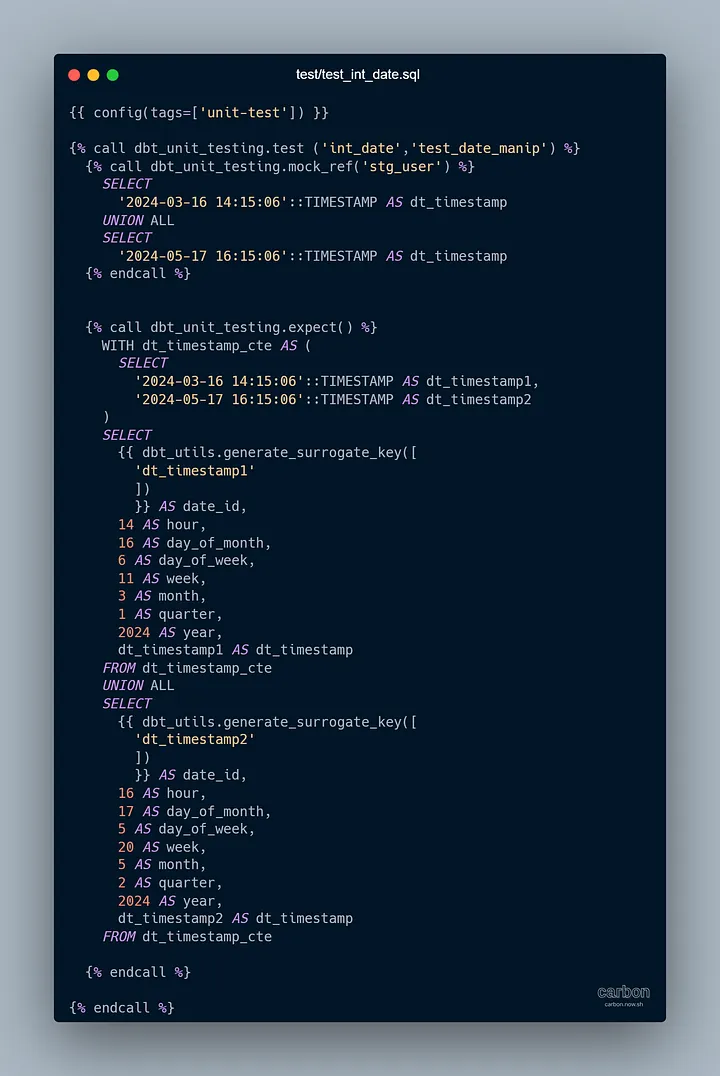
Я также создал несколько модульных тестов, просто чтобы протестировать.
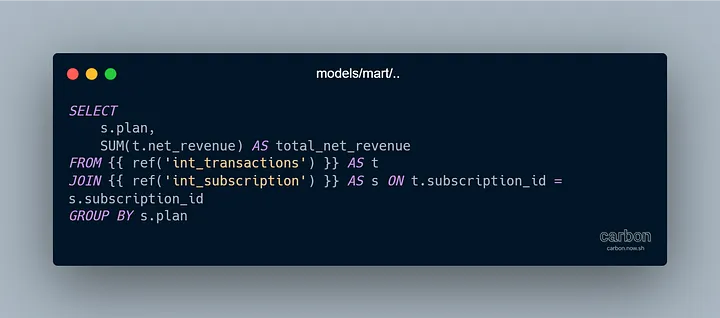
models/marts: здесь мы рассчитываем различные показатели, например общий чистый доход по плану подписки.
Мы закончили с DBT (пока что). Теперь перейдем к Airflow.
Airflow + Cosmos + DBT = история любви
Когда с DBT было покончено, нам нужно было перейти к следующему шагу — запланировать ежедневный запуск DBT-моделей и обновлять таблицы, чтобы дата-аналитики/сайентисты могли проводить анализ.
Вот тут-то и пригодился Airflow, особенно библиотека Cosmos, которая позволила легко запускать DBT-модели с помощью Airflow.
Как я уже говорил, Airbyte получал данные каждый день в 17:00, поэтому необходимо было запланировать запуск группы Airflow после 17:00 (каждое утро нам нужны свежие таблицы).
Вот как мы определили DAG с помощью Cosmos:
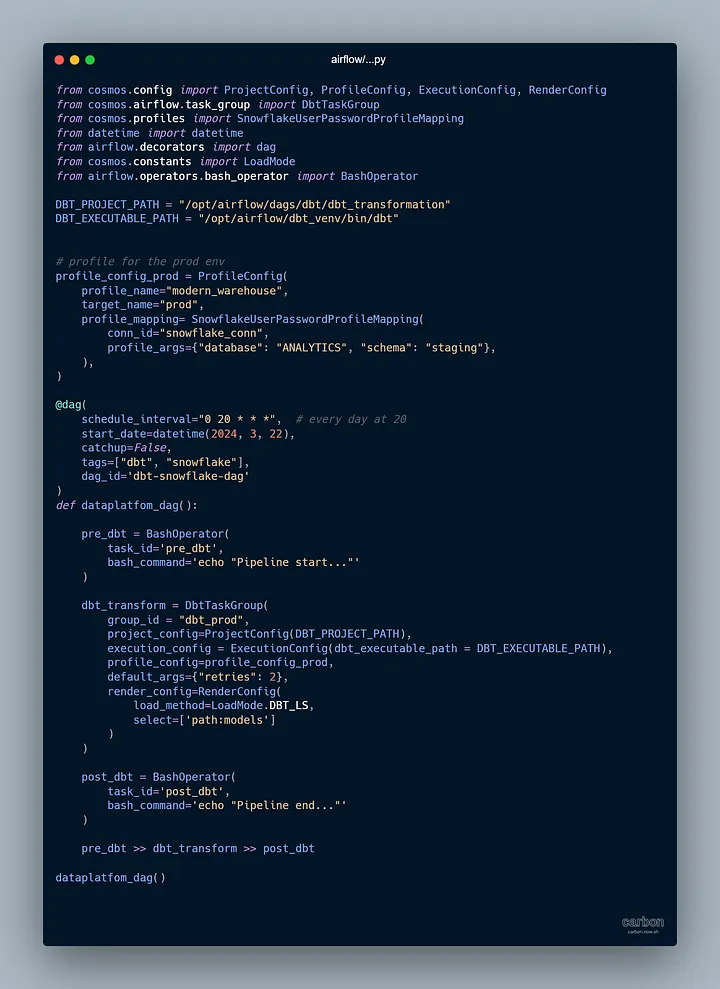
Не волнуйтесь, ссылка на репозиторий GitHub размещена в конце статьи.
Следующим шагом было развертывание кода Airflow на EC2 (который мы создали с помощью Terraform).
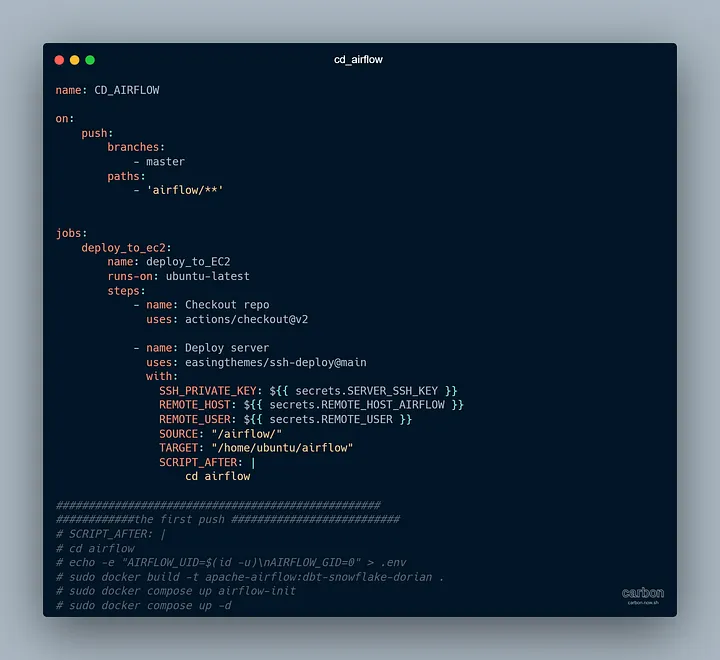
P. S. Часть SCRIPT_AFTER бесполезна.
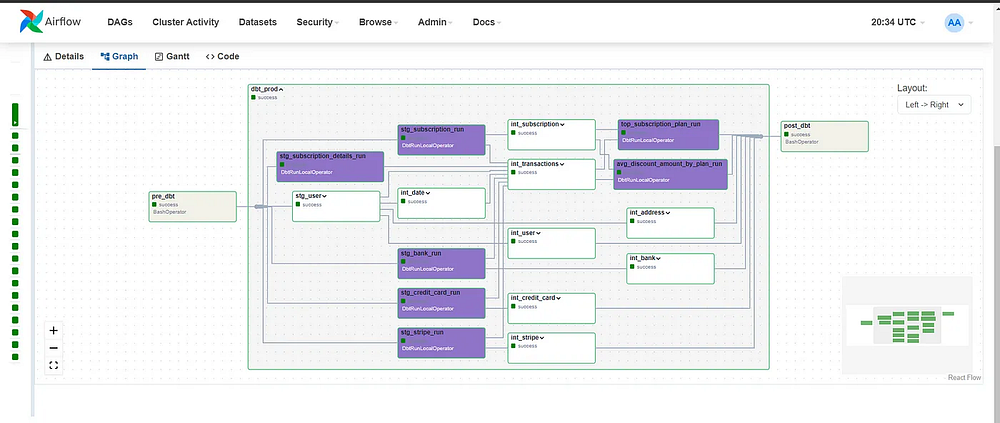
Можете нас поздравить: DAG теперь успешно работает (полюбуйтесь на этот красивый пользовательский интерфейс Airflow со всеми моделями), и таблицы будут обновляться ежедневно.
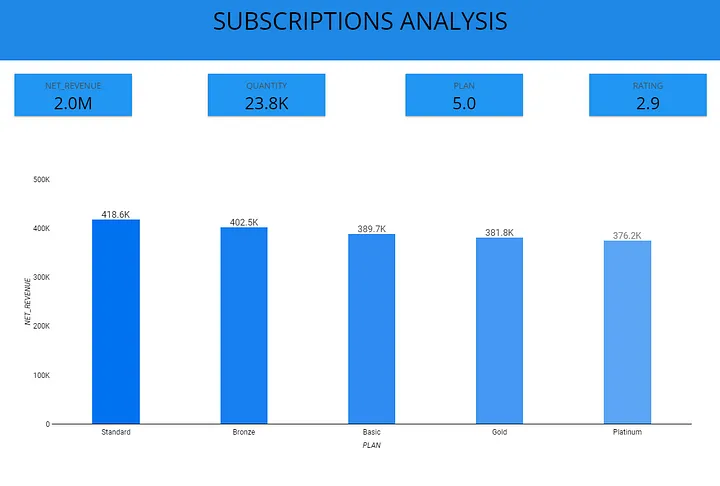
Дэшборд
Дэшборд я создал, руководствуясь знаменитым правилом KISS (“Кeep it simple stupid” — “Упрощай до примитива”).
Тут все по делу. Никаких вычурных визуальных эффектов или диаграмм.
Заключение
Я намеренно сделал эту статью очень простой и понятной.
Избегая слишком глубокого погружения в технические детали, я хотел, чтобы вы получили общее представление о типичном рабочем процессе инженера данных.
Ссылка на GitHub.