Паттерны проектирования генеративного ИИ: полное руководство.
Потребность в паттернах для ИИ
Все мы, создавая что-то новое, опираемся на проверенные методы, подходы и паттерны. Это утверждение особенно верно для тех, кто занимается разработкой программного обеспечения, однако в случае ИИ (и генеративного ИИ в частности) ситуация обстоит несколько иначе. При использовании таких новых технологий, как генеративный ИИ, не хватает хорошо задокументированных паттернов для обоснования решений.
В
Паттерны проектирования генеративного ИИ: полное руководство...
Потребность в паттернах для ИИ
Все мы, создавая что-то новое, опираемся на проверенные методы, подходы и паттерны. Это утверждение особенно верно для тех, кто занимается разработкой программного обеспечения, однако в случае ИИ (и генеративного ИИ в частности) ситуация обстоит несколько иначе. При использовании таких новых технологий, как генеративный ИИ, не хватает хорошо задокументированных паттернов для обоснования решений.
В этой статье я предлагаю несколько подходов и паттернов для генеративного ИИ, основанных на моей оценке бесчисленных производственных реализаций LLM в производстве. Цель приведенных паттернов — помочь минимизировать и преодолеть некоторые проблемы, связанные с реализацией генеративного ИИ, такие как высокие затраты, задержки и галлюцинации.
1. Многослойная стратегия кэширования, ведущая к тонкой настройке
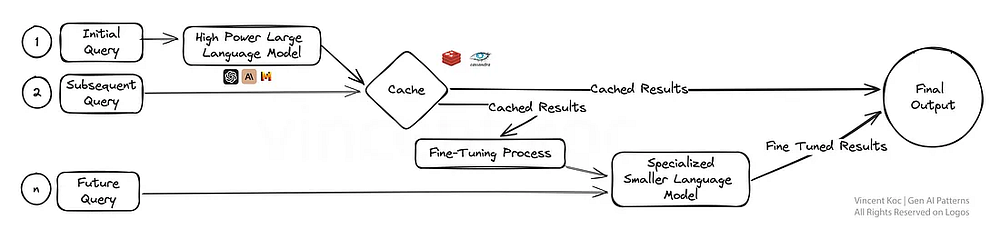
В данном случае мы решаем целый ряд проблем, связанных с высокой стоимостью, избыточностью и обучающими данными, посредством внедрения стратегии и сервиса кэширования для больших языковых моделей.
Кэшируя начальные результаты, система может быстрее выдавать ответы на последующие запросы, повышая эффективность модели. После получения достаточного количества данных наступает момент тонкой настройки, когда обратная связь от ранних взаимодействий используется для совершенствования специализированной модели.
Специализированная модель не только упрощает рабочий процесс, но и адаптирует опыт ИИ к конкретным задачам. Это повышает эффективность в тех сферах, где точность и адаптивность имеют первостепенное значение, например при обслуживании клиентов или создании персонализированного контента.
Для начала можно воспользоваться готовыми сервисами, такими как GPTCache, или создать собственный с помощью распространенных баз данных кэширования, таких как Redis, Apache Cassandra и Memcached. При добавлении дополнительных сервисов обязательно отслеживайте и измеряйте задержки.
2. Мультиплексирование агентов ИИ: разбиение на экспертные группы

Представьте экосистему, в которой несколько моделей генеративного ИИ (“агентов”) параллельно работают над запросом. Они ориентированы на решение конкретной задачи и каждый является специалистом в своей области. Такая стратегия мультиплексирования позволяет получить разнообразные ответы, которые затем интегрируются для формирования исчерпывающего ответа-результата.
Эта схема идеально подходит для решения сложных задач, когда различные аспекты требуют разного опыта. По такому же принципу работает и команда экспертов, в которой каждый занимается конкретной частью большой задачи.
Крупная модель (например, GPT-4) используется для понимания контекста и разбиения его на конкретные задачи или информационные запросы, которые передаются более мелким агентам. В качестве последних могут выступать небольшие языковые модели, такие как Phi-2 и TinyLlama, которые были обучены на конкретных задачах. Эти агенты имеют доступ к определенным инструментам или обобщенным моделям, таким как GPT и Llama, обладающим определенным характером, контекстными промптами и вызовами функций.
3. Тонкая настройка LLM для выполнения нескольких задач

Этот паттерн предполагает тонкую настройку большой языковой модели не на одной задаче, а на нескольких одновременно. Такой подход способствует надежному переносу знаний и навыков в различные области, повышая универсальность модели.
Это многозадачное обучение особенно полезно для платформ, которые должны выполнять различные задачи с высокой степенью компетентности, например для виртуальных ассистентов или исследовательских инструментов на базе ИИ. Такой метод может потенциально упростить рабочие процессы обучения и тестирования модели, работающей в сложной области.
В число ресурсов и пакетов для обучения LLM входят DeepSpeed, а также обучающие функции в библиотеке Transformer от Hugging Face.
4. Сочетание правил и генеративного подхода
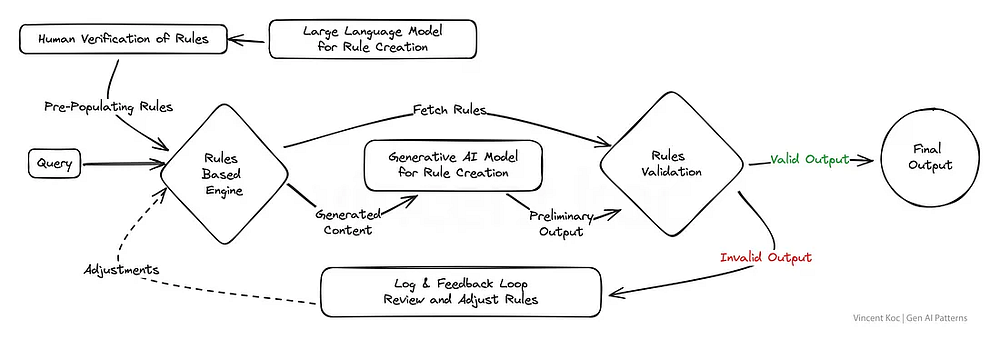
Ряд существующих бизнес-систем и корпоративных приложений все еще в некоторой степени основаны на правилах. Соединяя генеративный подход со структурированной точностью логики, основанной на правилах, этот паттерн позволяет создавать решения, которые одновременно демонстрируют креативность и в то же время соответствуют установленным требованиям.
Это мощная стратегия для тех сфер, где выходные данные должны соответствовать строгим стандартам или нормам. При этом обеспечивается соблюдение ИИ желаемых параметров, но в то же время он способен к инновациям и взаимодействию. Хорошим примером является генерация намерений и потоков сообщений для систем телефонной связи IVR или традиционных чат-ботов (не основанных на технологии LLM), которая базируется на правилах.
5. Использование графов знаний вместе с LLM
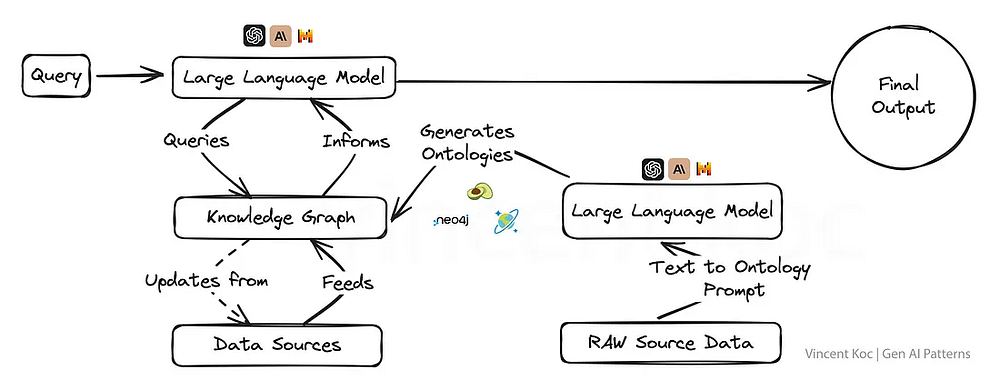
Интеграция графов знаний в модели генеративного ИИ дает им суперспособность ориентироваться на факты, позволяя получать результаты, которые не только учитывают контекст, но и более корректны с фактической точки зрения.
Такой подход крайне важен для приложений, где истина и точность не подлежат обсуждению, например при создании образовательного контента, медицинских рекомендаций или в любой другой области, где дезинформация может иметь серьезные последствия.
Графы знаний и онтологии графов (набор понятий для графа) позволяют преобразовать сложные темы или корпоративные задачи в структурированный формат, чтобы создать большую языковую модель с глубоким контекстом. Можно также использовать языковую модель для генерации онтологий в формате JSON или RDF (вот пример созданного мной промпта).
Для работы с графами знаний подходят сервисы графовых баз данных, такие как ArangoDB, Amazon Neptune, Azure Cosmos DB и Neo4j. Существуют также более широкие наборы данных и сервисы для доступа к более широким графам знаний: Google Enterprise Knowledge Graph API, PyKEEN Datasets и Wikidata.
6. Рой агентов искусственного интеллекта
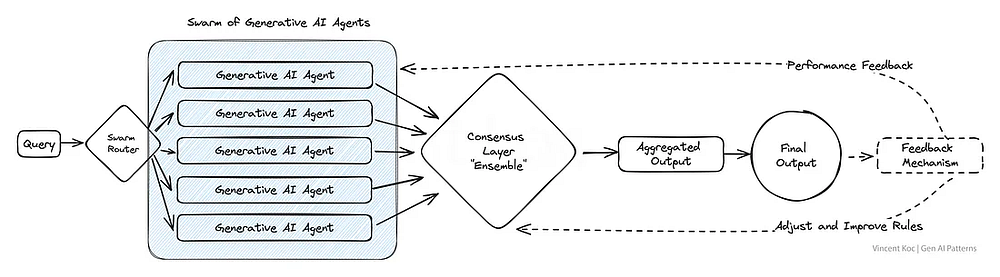
Источником вдохновения для создания этой схемы послужили рои насекомых и стада животных, которые повсеместно встречаются в природе. В данном паттерне задействуется множество агентов на базе ИИ, которые коллективно решают задачу, при этом каждый из них вносит свой уникальный вклад.
Полученный в результате совокупный результат отражает форму коллективного интеллекта, превосходящего то, чего мог бы достичь каждый агент по отдельности. Такой паттерн особенно полезен в сценариях, требующих широкого спектра творческих решений, или при работе со сложными наборами данных.
Примером этого паттерна может служить анализ научной статьи с точки зрения нескольких “экспертов” или оценка взаимодействия с клиентами по многим сценариям использования одновременно — от случаев мошенничества до коммерческих предложений. Мы берем этих коллективных “агентов” и объединяем все их входные данные вместе. При большом объеме роя можно использовать развертывание служб обмена сообщениями, таких как Apache Kafka, для обработки сообщений между агентами и службами.
7. Модульно-монолитный подход к LLM с возможностью компоновки
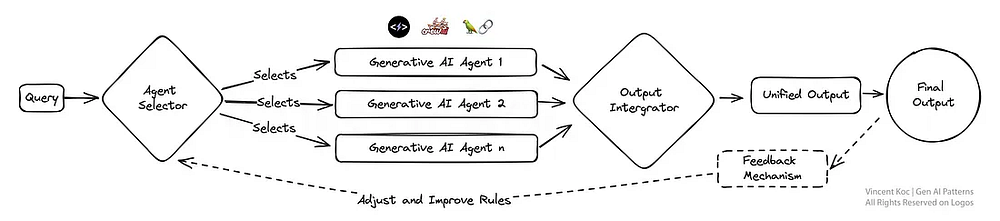
Этот дизайн — образец адаптивности: модульная система искусственного интеллекта может динамически перенастраиваться для оптимального выполнения задач. Такой паттерн сродни швейцарскому армейскому ножу: каждый модуль здесь можно выбрать и активировать по мере необходимости. Поэтому он очень эффективен для предприятий, которым требуются индивидуальные решения для разных типов взаимодействия с клиентами или потребностей в продукции.
Вы можете использовать различные фреймворки и архитектуры автономных агентов для разработки каждого из них и их инструментов. В качестве примера приведем фреймворки CrewAI, Langchain, Microsoft Autogen и SuperAGI.
Для модульного монолита в сфере продаж это могут быть агенты, занимающиеся работой с потенциальными клиентами: один — бронированием, другой — генерацией сообщений, третий — обновлением баз данных. В будущем, когда специализированные компании, занимающиеся разработкой ИИ, начнут предоставлять особые услуги, можно будет заменить модуль на внешний или сторонний сервис для решения определенного набора задач или специфических проблем.
8. Подход к постижению LLM памяти
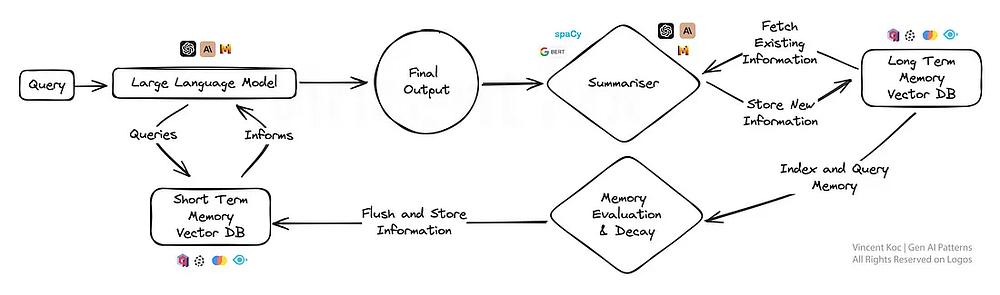
Такой подход привносит в ИИ элемент человеческой памяти, позволяя моделям вспоминать и строить на основе предыдущих взаимодействий более точные ответы.
Этот паттерн особенно полезен для постоянных бесед или сценариев обучения, поскольку ИИ со временем развивает более глубокое понимание, подобно специализированному персональному помощнику или адаптивной обучающей платформе. Подходы к постижению моделью памяти можно разрабатывать путем суммирования и сохранения ключевых событий и обсуждений в векторной базе данных с течением времени.
Чтобы сократить вычисления при таком суммировании, можно воспользоваться помощью небольших NLP-библиотек, таких как spaCy, или языковых моделей BART, если речь идет о значительных объемах. Базы данных используются векторные, а при извлечении на этапе промпта для проверки кратковременной памяти используется поиск по сходству для нахождения ключевых “фактов”. Если вам интересно рабочее решение, взгляните на продукт MemGPT с открытым исходным кодом, работающий по схожему образцу.
9. Двойная оценочная модель, состоящая из “синей” и “красной” команд
В оценочной модели, состоящей из “красной” и “синей” команд, один тип ИИ генерирует контент, а другой критически оценивает его, что напоминает строгий процесс рецензирования. Эта двойная модель отлично подходит для контроля качества, что делает ее применимой на платформах генерации контента, где важны достоверность и точность, например при агрегации новостей или создании образовательных материалов.
Этот подход можно использовать для частичной замены человеческой обратной связи при решении сложных задач с помощью точно настроенной модели, чтобы имитировать процесс рецензирования человеком и уточнить результаты для оценки сложных языковых сценариев и выходных данных.
Выводы
Приведенные паттерны проектирования генеративного ИИ — не просто шаблоны, а основы, на которых будут развиваться интеллектуальные системы будущего. По мере того как мы продолжаем исследовать и внедрять инновации, становится ясно, что выбранная архитектура определяет не только возможности, но и саму сущность создаваемого ИИ.
Данный перечень ни в коем случае не является чем-то окончательно сформировавшимся. Мы будем наблюдать за развитием этой сферы по мере расширения паттернов и сценариев использования генеративного ИИ.