Создание и оценка базовых и продвинутых RAG-приложений с помощью LlamaIndex и Gemini Pro в Google Cloud. Часть 1.
Генерация текстов с дополнительным извлечение информации (Retrieval-Augmentation Generation, RAG) — это эффективный метод получения релевантных ответов на пользовательские вопросы.
Чтобы создать высококачественную систему RAG, используемую в производстве, необходимо учесть следующие факторы. Эффективные методы извлечения данных. Выбор эффективной стратегии извлечения данных и/или генерации обеспечивает LLM высокорелевантным контекстом для г
Создание и оценка базовых и продвинутых RAG-приложений с помощью LlamaIndex и Gemini Pro в Google Cloud. Часть 1...
Генерация текстов с дополнительным извлечение информации (Retrieval-Augmentation Generation, RAG) — это эффективный метод получения релевантных ответов на пользовательские вопросы.
Чтобы создать высококачественную систему RAG, используемую в производстве, необходимо учесть следующие факторы.
- Эффективные методы извлечения данных. Выбор эффективной стратегии извлечения данных и/или генерации обеспечивает LLM высокорелевантным контекстом для генерации ответов.
- Комплексная система тестирования. Помогает эффективно итерировать и оптимизировать системы RAG как на этапе первоначальной разработки, так и после развертывания.
В недавнем исследовательском отчете о RAG перечислены ключевые передовые технологии, позволяющие повышать качество извлечения данных в RAG-пайплайнах путем внедрения стратегий пред- и пост-извлечения.
В этом руководстве рассмотрим этапы создания и тестирования базового RAG-пайплайна. Для этого будем использовать фреймворк LlamaIndex, модель Gemini Pro и триаду метрик TruLens — системы оценки эффективности RAG-приложения путем вычисления релевантности контекста, релевантности ответа и его обоснованности.
Предварительные условия и настройка
Для создания ноутбука в данном примере использована среда Google Cloud Colab.
Для работы этого ноутбука требуется разрешение на загрузку и выгрузку файлов из Google Cloud Storage.
1. Установка необходимых пакетов в ноутбук
Примечание: для обеспечения совместимости необходимо установить соответствующие версии пакетов: фреймворка данных LlamaIndex, системы тестирования TruLens и библиотеки LiteLLm, позволяющей использовать TruLens и упрощающей выполнение задач LLM и эмбеддинг-вызовов.
!pip install pypdf cohere llama-index==0.9.48 google-generativeai trulens_eval==0.22.1 litellm==1.23.10 torch sentence-transformers
2. Настройка переменных окружения для API-ключей
Вам необходимо получить API-ключ в Google AI Studio. Получив API-ключ, можете либо передать его модели явно, либо использовать переменную среды GOOGLE_API_KEY.
%env GOOGLE_API_KEY=...
%env GEMINI_API_KEY=..
3. Импорт ключей
import os
GOOGLE_API_KEY = "" # добавьте сюда ключ GOOGLE API
GEMINI_API_KEY = "" # добавьте сюда ключ GEMINI API
os.environ["GOOGLE_API_KEY"] = GOOGLE_API_KEY
os.environ["GEMINI_API_KEY"] = GEMINI_API_KEY
4. Применение метода Gemini().completion для взаимодействия с Gemini
Это позволит передавать Gemini запросы для генерации необходимых текстов.
from llama_index.llms import Gemini
resp = Gemini().complete("Write a poem about a magic backpack")
print(resp)
После установки соединения с Gemini LLM начнем работу над RAG-пайплайном.
5. Авторизация в Google Cloud Storage
Здесь хранятся артефакты и другие документы, необходимые для выполнения исследовательской работы.
from google.colab import auth
auth.authenticate_user()
6. Импорт файла utils как модуля
Этот модуль содержит предварительно созданные функции обратной связи и другие утилиты, которые помогут выполнить тесты, описанные далее.
!gsutil cp gs://machine-learning-gemini/utils.py .
import importlib
importlib.import_module('utils')
Что такое базовый RAG-пайплайн?
После загрузки в RAG-пайплайн данные подготавливаются для пользовательских запросов, то есть индексируются. Запрос пользователя взаимодействует с индексом, в результате чего данные отфильтровываются по наиболее релевантному контексту. Затем этот контекст и запрос отправляются в LLM вместе с промптом, и LLM выдает ответ на основе контекста.
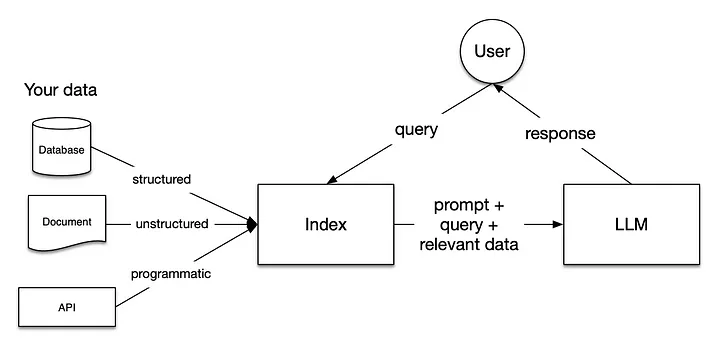
Шаги по созданию базового RAG-пайплайна
Перед началом работы убедитесь, что PDF-файлы и файлы утилит, упомянутые в папке utils, загружены в ваш облачный проект Google, к которому у вас есть доступ.
1. Загружаем PDF-файл с помощью утилиты командной строки gsutil в ноутбук Colab. Этот PDF-файл (неструктурированный документ) будем использовать в качестве контекста для модели Gemini Pro, с которой ранее установлено соединение.
Примечание: можно также использовать PDF-файл и тестовые вопросы (релевантные предоставленному контексту) для этого учебного проекта.
!gsutil cp gs://machine-learning-gemini/eBook-How-to-Build-a-Career-in-AI.pdf
2. Подаем PDF-документ, разбиваем его на фрагменты (чанки), создаем эмбеддинги с помощью модели и проводим индексацию, используя VectorStoreIndex.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
print(type(documents), "\n")
print(len(documents), "\n")
print(type(documents[0]))
print(documents[0])
print(documents[1])
3. Объединим 41 PDF-страницу в один документ, чтобы обеспечить точность разделения текста при использовании более сложных методов извлечения информации.
from llama_index import Document
document = Document(text="\n\n".join([doc.text for doc in documents]))
4. Создадим индекс, используя VectoreStore Index в LlamaIndex. Определим LLM и эмбеддинг-модель.
Примечание: будем использовать эмбеддинг-модель HuggingFace.
from llama_index import VectorStoreIndex
from llama_index import ServiceContext
from llama_index.llms import Gemini
llm = Gemini(model="models/gemini-pro", temperature=0.1)
# Создание контекста сервиса с помощью LLM Gemini и модели
service_context = ServiceContext.from_defaults(
llm=llm, embed_model="local:BAAI/bge-small-en-v1.5"
)
index = VectorStoreIndex.from_documents([document],
service_context=service_context)
5. Из этого индекса получаем механизм обработки запросов, позволяющий передавать пользовательские запросы, по которым выполняется извлечение данных при синтезе с загруженным PDF-документом.
query_engine = index.as_query_engine()
Попробуем выполнить первый запрос с помощью этого механизма обработки запросов.
response = query_engine.query(
"What are steps to take when finding projects to build your experience?"
)
print(str(response))
Теперь, когда создан базовый RAG-пайплайн, проведем его тестирование с помощью триады метрик RAG. Это позволит выяснить, насколько эффективно работает базовый RAG-пайплайн в сравнении с продвинутыми методами извлечения данных, которые будут рассмотрены во второй части.
Чтобы протестировать RAG-приложение, будем использовать систему TruLens для инициализации функций обратной связи. Это тестирование предполагает параллельное сравнение между запросом, ответом и контекстом.
Создадим три функции обратной связи — релевантность контекста, релевантность ответа и обоснованность ответа — в качестве утилит в файле utils.
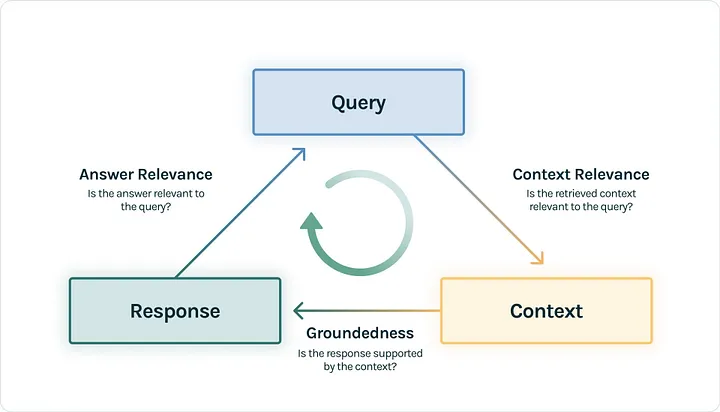
6. Создадим тестовые вопросы, которые послужат для тестирования приложения.
Примечание: в папке utils есть набор тестовых вопросов для оценки ответов модели.
Загрузите этот файл, добавив, если необходимо, дополнительные вопросы.
!gsutil cp gs://machine-learning-gemini/eval_questions.txt .
7. Теперь нужно инициализировать модуль TruLens, чтобы начать процесс инициализации и сбросить базу данных TruLens, в которой хранятся результаты.
from IPython.display import JSON
from trulens_eval import Tru, Feedback
tru = Tru()
tru.reset_database()
LLM становятся стандартным инструментом для масштабной оценки приложений генеративного ИИ, позволяя не полагаться исключительно на тесты и бенчмарки, требующие дорогостоящих человеческих ресурсов. Кроме того, эта технология позволяет проводить анализ пользовательских доменов в приложениях, динамично реагируя на меняющиеся требования к данным.
8. Используем кастомизированный регистратор TruLens для записи оценок во время выполнения бенчмарков, представляющих собой предварительно загруженные функции RAG (релевантность контекста, релевантность ответа и обоснованность ответа). Указываем также, что будем отслеживать эту версию приложения для последующего сравнения.
from utils import get_prebuilt_trulens_recorder
tru_recorder = get_prebuilt_trulens_recorder(query_engine,
app_id="Direct Query Engine")
9. Запустим механизм обработки запросов с контекстом TruLens, заданным ранее.
with tru_recorder as recording:
for question in eval_questions:
response = query_engine.query(question)
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
Примечание: полный набор результатов смотрите в ноутбуке.

Что здесь происходит?
Каждый запрос-промпт из набора eval отправляется в механизм обработки запросов. А регистратор TruLens в фоновом режиме оценивает каждый из запросов по трем метрикам.
Мы видим список запросов, связанных с соответствующими ответами, и то, насколько хорошо они справились с этими функциями.
10. Запустим дэшборд TruLens с помощью Streamlit, чтобы просмотреть на нем все результаты.
tru.run_dashboard()
Дэшборд будет выглядеть примерно так:
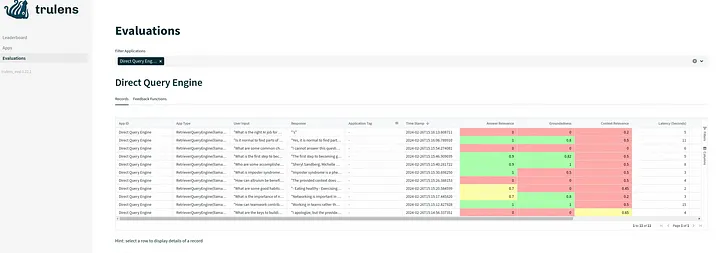
Продолжим подробно изучать продвинутые техники во 2-й части.