Долгожданные инструкции Switch-Case в Python.
Python 3.10 обрел немало интересных возможностей, одна из которых привлекла мое внимание в особенности — структурное сопоставление с шаблоном, иначе говоря инструкции switch/case.
Несмотря на свою повсеместность в большинстве языков, в Python инструкции switch до сих пор отсутствовали.
Еще в 2006 году создавалось предложение PEP 3103, в котором рекомендовалось реализовать поддержку инструкций switch-case. Однако в результате опроса на PyCon 2007 эта функция
Долгожданные инструкции Switch-Case в Python...
Python 3.10 обрел немало интересных возможностей, одна из которых привлекла мое внимание в особенности — структурное сопоставление с шаблоном, иначе говоря инструкции switch/case.
Несмотря на свою повсеместность в большинстве языков, в Python инструкции switch до сих пор отсутствовали.
Еще в 2006 году создавалось предложение PEP 3103, в котором рекомендовалось реализовать поддержку инструкций switch-case. Однако в результате опроса на PyCon 2007 эта функция не получила достаточной поддержки, и разработчики ее отложили.
Гораздо позднее уже в 2020 году Гвидо Ван Россум, создатель Python, опубликовал первую документацию, описывающую новые инструкции switch, технику, которая, согласно PEP 634, была названа как структурное сопоставление с шаблоном.
Однако, как вы вскоре увидите, здесь нам предлагается намного большее, нежели просто инструкции switch-case (что подразумевает match-case).
Посмотрим, как эта логика работает.
1. Структурное сопоставление с шаблоном
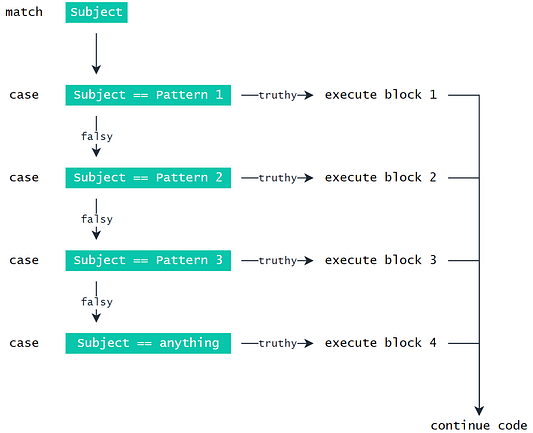
Сопоставление подразумевает определение при операторе match искомого значения, после которого можно перечислить несколько потенциальных кейсов, каждый с оператором case. В месте обнаружения совпадения между match и case выполняется соответствующий код.
Например:
http_code = "418" match http_code: case "200": print("OK") do_something_good() case "404": print("Not Found") do_something_bad() case "418": print("I'm a teapot") make_coffee() case _: print("Code not found")Здесь происходит проверка нескольких условий и выполнение разных операций на основе значения, которое мы находим внутри http_code.
Сразу становится очевидным, что “да”, можно выстроить ту же логику, используя набор инструкций if-elif-else:
http_code = "418" if http_code == "418": print("OK") do_something_good() elif http_code == "404": print("Not Found") do_something_bad() elif http_code == "418" print("I'm a teapot") make_coffee() else: print("Code not found")Тем не менее, с помощью инструкций match-case мы избавляемся от повторения http_code ==, что повышает чистоту кода при тестировании на соответствие многим разным условиям.
Другой пример
В PEP 635 есть отличные примеры инструкций match-case, повышающих читаемость кода. Один из этих примеров показывает, как использовать эту инструкцию для проверки типа и структуры субъекта:
match x: case host, port: mode = "http" case host, port, mode: passЗдесь мы ожидаем получения деталей соединения в формате кортежа и присваиваем данные значения правильным переменным.
В этом случае, если mode соединения в кортеже не определен (например, было передано только два значения — host и port), мы предполагаем, что режим соединения http.
Тем не менее в других случаях можно ожидать, что режим будет определен явно. Тогда вместо этого мы получаем кортеж, наподобие (<host>, <port>, "ftp"), и mode уже не устанавливается как http .
Если же мы пропишем ту же логику с помощью if-else, то получится вот что:
if isinstance(x, tuple) and len(x) == 2: host, port = x mode = "http" elif isinstance(x, tuple) and len(x) == 3: host, port, mode = xПредпочесть можно любой из этих вариантов, но лично для меня реализация через match-case выглядит намного чище.
Реальный пример с форматом JSON
Еще один интересный случай — это способность по-разному парсить объекты словаря в зависимости от их структуры. Отличным тестовым примером будет парсинг датасета SQuAD 2.
Этот датасет представляет чрезвычайно популярный набор пар вопрос-ответ, используемых для обучения моделей МО отвечать на вопросы. Скачать его можно так:
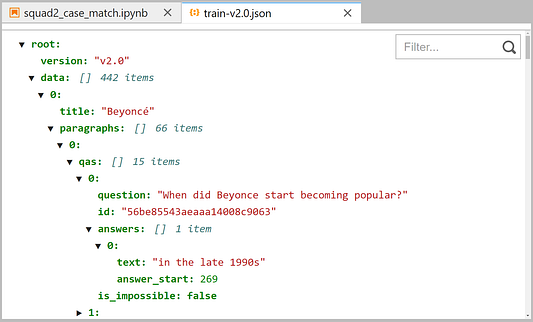
{ "cells": [ { "cell_type": "code", "execution_count": 1, "id": "cellular-horror", "metadata": {}, "outputs": [], "source": [ "import requests\n", "import json" ] }, { "cell_type": "code", "execution_count": 2, "id": "operational-techno", "metadata": {}, "outputs": [], "source": [ "url = 'https://rajpurkar.github.io/SQuAD-explorer/dataset/'\n", "file = 'train-v2.0.json'" ] }, { "cell_type": "code", "execution_count": 3, "id": "successful-cornwall", "metadata": {}, "outputs": [], "source": [ "res = requests.get(f'{url}{file}')\n", "# write to file\n", "with open(file, 'wb') as f:\n", " for chunk in res.iter_content(chunk_size=4):\n", " f.write(chunk)" ] } ], "metadata": { "kernelspec": { "display_name": "Python 3", "language": "python", "name": "python3" }, "language_info": { "codemirror_mode": { "name": "ipython", "version": 3 }, "file_extension": ".py", "mimetype": "text/x-python", "name": "python", "nbconvert_exporter": "python", "pygments_lexer": "ipython3", "version": "3.10.0a6" } }, "nbformat": 4, "nbformat_minor": 5 }Если взглянуть на структуру SQuAD, то очевидно, что она состоит из нескольких уровней, и это потребуется учесть при парсинге:
Проблема же в том, что не все образцы используют одинаковый формат словаря.
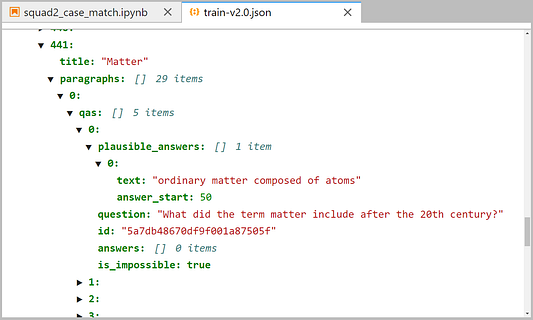
Если взглянуть на несколько последних, то мы видим, что список qas содержит и answers, и plausible_answers, в то время как в предыдущих образцах присутствуют только answers:
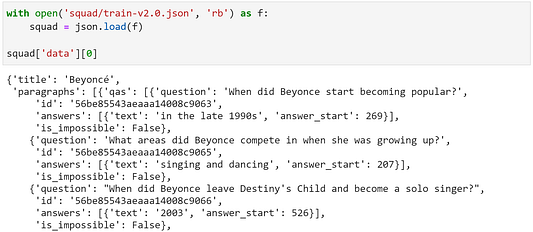
Попробуем с помощью match-case создать более чистую альтернативу тяжелой логике if-else, необходимой для обработки всего этого. Сначала загружаем данные:
Данный JSON-файл содержит несколько слоев. После обращения к squad['data'] нужно перебрать каждую group вопросов, затем каждый paragraph, а затем все qas (вопрос-ответы). Выглядеть это будет так:
for group in squad['data']: for paragraph in group['paragraphs']: for qa in paragraph['qas']: # вставить код сюдаА здесь начинается самое интересное. Используя логику if-else, мы получим следующее:
{ "cells": [ { "cell_type": "code", "execution_count": 1, "id": "harmful-excuse", "metadata": {}, "outputs": [ { "data": { "text/plain": [ "([('When did Beyonce start becoming popular?', 'in the late 1990s'),\n", " ('What areas did Beyonce compete in when she was growing up?',\n", " 'singing and dancing'),\n", " (\"When did Beyonce leave Destiny's Child and become a solo singer?\", '2003'),\n", " ('In what city and state did Beyonce grow up? ', 'Houston, Texas'),\n", " ('In which decade did Beyonce become famous?', 'late 1990s')],\n", " [('Physics has broadly agreed on the definition of what?', 'matter'),\n", " ('Who coined the term partonic matter?', 'Alfvén'),\n", " ('What is another name for anti-matter?', 'Gk. common matter'),\n", " ('Matter usually does not need to be used in conjunction with what?',\n", " 'a specifying modifier'),\n", " ('What field of study has a variety of unusual contexts?', 'physics')])" ] }, "execution_count": 1, "metadata": {}, "output_type": "execute_result" } ], "source": [ "new_squad = []\n", "\n", "for group in squad['data']:\n", " for paragraph in group['paragraphs']:\n", " for qa in paragraph['qas']:\n", " question = qa['question']\n", " if 'answers' in qa.keys() and len(qa['answers']) > 0:\n", " answers = qa['answers'][0]['text']\n", " elif 'plausible_answers' in qa.keys() and len(qa['plausible_answers']) > 0:\n", " answers = qa['plausible_answers'][0]['text']\n", " else:\n", " answers = None\n", " new_squad.append((question, answers))\n", "\n", "new_squad[:5], new_squad[-5:]" ] } ], "metadata": { "kernelspec": { "display_name": "Python 3", "language": "python", "name": "python3" }, "language_info": { "codemirror_mode": { "name": "ipython", "version": 3 }, "file_extension": ".py", "mimetype": "text/x-python", "name": "python", "nbconvert_exporter": "python", "pygments_lexer": "ipython3", "version": "3.10.0a6" } }, "nbformat": 4, "nbformat_minor": 5 }Не очень красиво, но работает. Теперь перепишем все это с помощью match-case:
{ "cells": [ { "cell_type": "code", "execution_count": 4, "metadata": {}, "outputs": [], "source": [ "# initialize list where we will place all of our data\n", "new_squad = []\n", "\n", "# we need to loop through groups -> paragraphs -> qa_pairs\n", "for group in squad['data']:\n", " for paragraph in group['paragraphs']:\n", " for qa_pair in paragraph['qas']:\n", " # we pull out the question\n", " question = qa_pair['question']\n", " # now the NEW match-case logic to check if we have 'answers' or 'plausible_answers'\n", " match qa_pair:\n", " case {'answers': [{'text': answer}]}:\n", " # because the case pattern assigns 'answer' for us, we pass\n", " pass\n", " case {'plausible_answers': [{'text': answer}]}:\n", " # we perform same check but for 'plausible_answers'\n", " pass\n", " case _:\n", " # this is our catchall, we will set answer to None\n", " answer = None\n", " # append dictionary sample to parsed squad\n", " new_squad.append({\n", " 'question': question,\n", " 'answer': answer\n", " })" ] } ], "metadata": { "kernelspec": { "display_name": "Python 3", "language": "python", "name": "python3" }, "language_info": { "codemirror_mode": { "name": "ipython", "version": 3 }, "file_extension": ".py", "mimetype": "text/x-python", "name": "python", "nbconvert_exporter": "python", "pygments_lexer": "ipython3", "version": "3.8.5" } }, "nbformat": 4, "nbformat_minor": 5 }Определенно выглядит менее загруженно и является отличной альтернативой изначальному варианту логики парсинга.
Лично я считаю, что этот новый синтаксис очень неплох, хотя использую его 50/50. Уверен, как только больше пользователей начнут применять match-case, сообщество быстро выработает определенный консенсус и оптимальные подходы к реализации.
Ну а пока, этот вариант просто выглядит круто — я восхищен!
Спасибо за внимание!